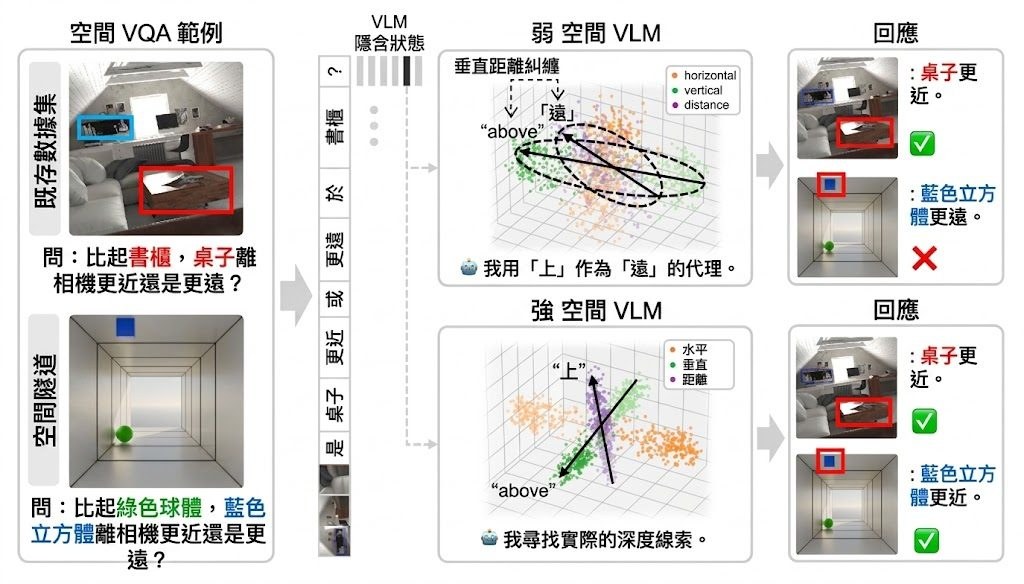
contrastive-probing 是一個用來檢查 Vision-Language Models(VLMs)內部空間表示的輕量項目,焦點不是模型答對幾多題,而是它腦內如何分開 left / right、above / below、far / close。它沿用論文《Why Far Looks Up: Probing Spatial Representation in Vision-Language Models》的 contrastive probing 方法,透過交換問題中的兩個物件,再比較 hidden states 差異,抽出 Δ vectors 作分析。
使用時,做法是把一張圖片配上一條原始空間問題,再生成一條交換 obj1 ↔ obj2 的對照問題,之後對同一個 VLM 跑兩次 forward,並在每層 transformer 擷取最後 token 的表示。這個流程可配合 🤗 transformers 載入的模型,然後輸出 Axis Coherence、6×6 Δ-similarity heatmap、2D/3D PCA 視覺化,以及 Vertical–Distance Entanglement Index(VD-EI)等結果。
這個項目解決的核心問題,是 benchmark accuracy 往往只告訴你模型有冇答中,卻未必揭示它是否用對了空間線索。論文與附帶說明指出,多個模型家族都出現 vertical-distance entanglement,也就是把畫面較高的位置誤當成較遠,反映自然照片常見的 perspective heuristic「higher in the image ⇒ farther away」。
- 用最少對照設計觀察表示層,而不只看答題分數
- 可比較不同 layer 的空間軸是否清晰分離
- 能發現 vertical 與 distance 是否糾纏,幫助找出偏差來源
- 適合分析 EmbSpatial-Bench、SpatialTunnel 這類空間推理資料
對研究者、模型分析人員,或者要檢查 multimodal assistant、robotics、embodied agents 背後空間推理可靠性的人,這個項目尤其有用。現有資料顯示,就算 benchmark 分數相近,不同 VLM 的內部表示也可能差很遠,而空間軸分得較清楚的模型,通常在不同測試上的穩健性會較好。
整體來看,這不是訓練新模型的項目,而是一套偏向診斷與解釋的工具。它的創新點在於用 minimal contrastive pairs 加上 representation-level analysis,把「模型為何會答對或答錯」拆成更具體的內部結構問題,對想深入理解 VLM 空間能力的人,價值比單看排行榜更高。
GitHub: https://github.com/cheolhong0916/contrastive-probing
項目: https://cheolhong0916.github.io/whyfarlooksup.github.io/