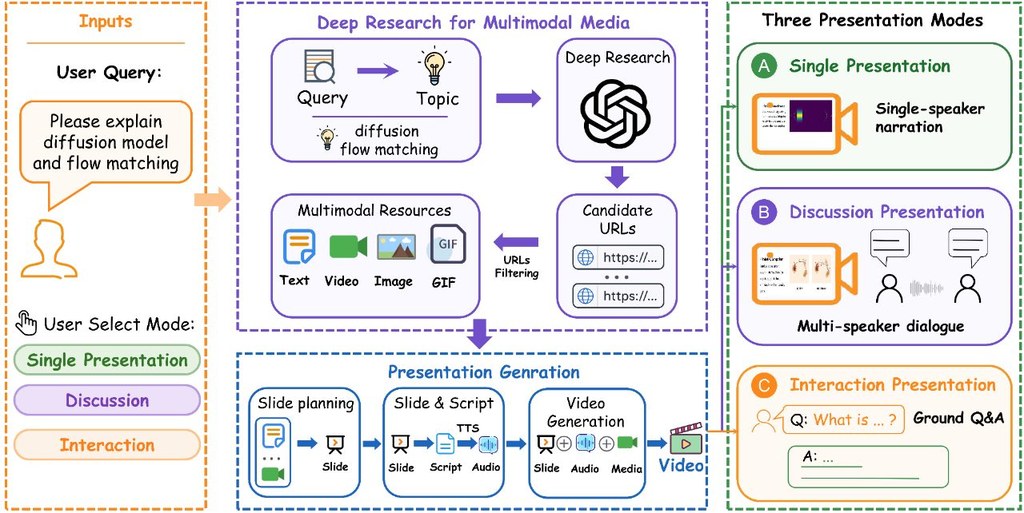
如果你有留意大型語言模型,應該知道文字愈長,運算成本往往升得愈快。Lighthouse Attention 針對的正正是這個痛點:在極長上下文訓練時,用分層挑選的方法,先縮細需要重點處理的內容,再交回現成的高效注意力流程處理。
這個儲存庫不是一個即開即用的聊天程式,而是建基於 PyTorch 的 torchtitan 訓練框架之上,以補丁形式整合。換句話說,較適合本身已經做模型訓練、想比較不同注意力機制的人;一般用家未必會直接跑起,但讀它的設計仍很有參考價值。
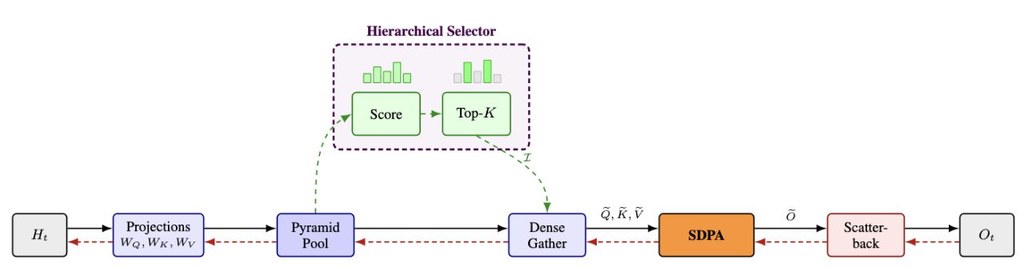
它較特別的地方,在於不是把稀疏機制硬塞進自訂核心,而是先做選擇,再沿用現有的 FlashAttention 密集計算路線。這樣的好處是較易受惠於上游優化,也減少為新方法重寫整套底層核心的負擔。資料顯示,它提供 norm、dilated 和 gla 三種評分變體,亦支援可選的 context parallel 路徑。
如果你想上手,較實際的做法是先把它當成研究原型:按版本要求準備好 torchtitan、對應提交版本、兩個額外原始檔及補丁,再用 configs 內不同設定比較 top-K、pool、大細層數與 scorer 差異。官方資訊亦提到,它曾在 530M Llama-3 規模、以及最高百萬 token 訓練情境下驗證。
重點可以這樣看:
– 主要用途是降低超長上下文訓練時的注意力成本
– 核心做法是分層挑選重要片段,再交由密集注意力計算
– 已列出多組可比較設定:top-K、pool、levels、scorer、CP
– 相關評分或路線包括 norm、dilated、gla
– 較適合模型研究、訓練基建開發及長文本實驗場景
只要是標準的 decoder-only Transformer / causal LM,基本都可以替換它的 Q/K/V self-attention 層。
判斷標準
只要模型滿足下面幾點,就通常能做這種替換:
有 self-attention 層,而不是依賴複雜的外部編碼器。
層裡能清楚找到 q_proj / k_proj / v_proj 或等價實現。
是 decoder-only 架構,使用 causal mask。
沒有把 attention 邏輯寫死成特別難拆的自定義模塊。
最適合的模型類型
Llama 系列:最常見,結構標準,Q/K/V 分明,最容易改。
Qwen 系列:也是標準 decoder-only 路線,通常同樣適合做 attention 替換。
Mistral 系列:同樣屬於 decoder-only LLM,理論上也適合。
GPT-style / LLaMA-style 自回歸模型:只要是單向 causal attention,一般都能改。
整體來說,Lighthouse Attention 最吸引之處,不只是追求更快,而是嘗試在訓練期保留與現有生態的相容性。對需要探索 98K、512K 甚至更長上下文訓練的人,它是一個值得細看、但明顯偏研究與工程用途的專案。