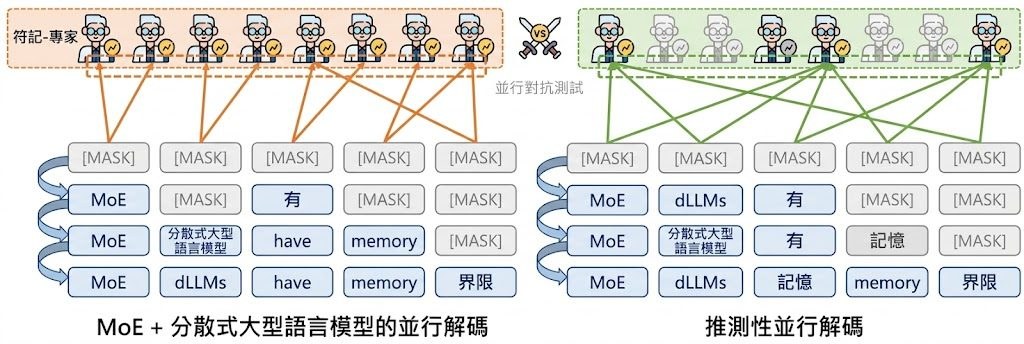
擴散式大型語言模型(dLLMs)近年被視為自迴歸模型的另一條路線,本身就支援平行解碼,但一旦搭配 MoE(Mixture-of-Experts)架構來放大模型容量,卻會撞上一個尷尬的牆:dLLM 在同一個前向傳遞中會同時處理多個互相關聯的 token,而傳統 MoE 卻是針對每個 token 各自挑選專家,導致一次推論要啟動的獨立專家數量暴增,記憶體頻寬很快就成為瓶頸。
dMoE 的核心構想相當直觀:與其在每個 token 層級各自決定要用哪個專家,不如在「區塊」層級做統一決策。它會先把同一個區塊內各 token 的專家分佈聚合成一份,再以這個區塊級的分佈去引導整個區塊的路由。這個改動讓啟動的獨立專家數量從原本的 69.5 個左右壓到 14.6 個,記憶體用量減少約 76% 至 80%,端到端延遲也獲得 1.14 倍到 1.66 倍的加速。
在效能維持方面,dMoE 在多項推理與通用基準測試中保留了原模型約 99.11% 的表現。以 MATH500 為例,成績只從 72.0% 微跌到 71.0%,啟動專家數量卻從 70 個降到 14.1 個,是相當划算的交換。
dMoE 直接以 LLaDA-2.0-mini 為基礎建構,沒有更動主架構,因此可順利套用到其他遮罩式 dLLMs,目前亦已在 Hugging Face 上釋出名為 dMoE-16B 的模型權重。對想嘗試 dLLM 卻受限於顯卡的研究者與工程師來說,這個項目是低門檻的延伸切入點;對做模型效率優化的團隊,區塊級路由的設計也提供了有參考價值的方向。
重點摘要
- 區塊級專家路由:在區塊而非 token 層級做 MoE 決策,大幅壓低啟動專家數量。
- 記憶體與頻寬壓力減輕:獨立專家從約 69.5 個降到 14.6 個,記憶體用量減少 76%–80%。
- 速度明顯提升:端到端推論延遲獲得 1.14× 至 1.66× 加速。
- 表現幾乎不打折:在多項基準測試中保留約 99.11% 原始效能。
- 隨插即用設計:以 LLaDA-2.0-mini 為基礎,不改動架構即可套用至其他遮罩式 dLLMs。
GitHub: https://github.com/fscdc/dMoE