如果你對「AI識答數學題」有興趣,SU-01是一個幾有代表性的案例。它是一個 30B-A3B 推理模型,目標不是單靠背答案,而是嘗試完成較長步驟、較講求證明結構的數學與科學題目,尤其接近競賽題風格。
對一般讀者而言,最易理解的用法,是把它當成一個專注於複雜解題的模型來看,而不是萬能聊天機械人。官方資訊顯示,模型已公開權重,亦有技術報告與專案頁面;如果你本身會用 Hugging Face 一類平台,就可以進一步了解它的輸出表現與測試方式。
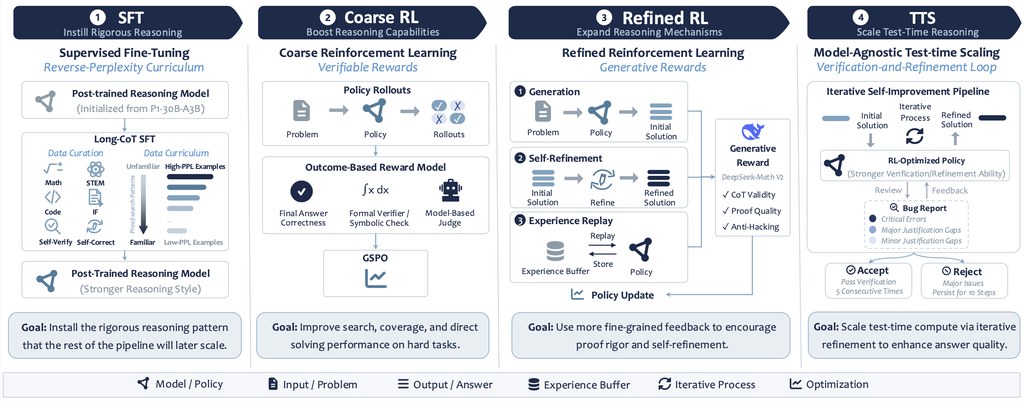
SU-01較特別的地方,在於它不依賴外部工具、寫程式執行,或者專門符號求解器,仍然想把長鏈條推理做好。訓練上,它用了較有策略的資料排序方式,以及分兩階段強化學習,先追求可驗證答案,再逐步改善證明質素,這點對處理多步驟題目尤其重要。
- 重點放在數學、物理等需要嚴謹步驟的解題
- 嘗試處理長篇推理與證明修正,而非只輸出最終答案
- 在 IMO 2025(第66屆國際數學奧林匹亞)、USAMO 2026(美國數學奧林匹亞)、IPhO 2024/2025 有高水準成績
- 相關模型可留意同類推理系統,例如 DeepSeek-R1、OpenAI o1 類型模型,以及其他數理導向大型語言模型
如果你是研究員、教育科技開發者,或者想比較不同推理模型在高難度題目的差異,SU-01很值得觀察。對一般學生來說,它未必是即開即用的溫習工具,但作為理解 AI 如何由「識答題」走向「識證明」的例子,參考價值相當高。
整體來看,SU-01吸引之處不只在分數,而是在方法上走一條相對簡潔統一的路線。從公開資料判斷,它更像是一個展示「後訓練如何提升嚴謹推理」的研究型專案,適合關心 AI 推理上限的人細看。