PerceptionRubrics 是一個多模態評測框架兼資料集,主力檢查 Multimodal Large Language Models 是否真正看清圖片內容,而唔係只係在傳統 benchmark 拿到高分。它要解決的問題很直接:現有 caption 評測常用 holistic semantic matching 或平均分,容易把嚴重錯誤沖淡,但人類閱讀結果時,關鍵事實一錯,整體輸出已經未必可信。
作者把舊有範式拆開重做,改用 atomic auditing,把每張圖分解成可核實的細項,再分成 Must-Right 與 Easy-Wrong 兩條 rubric 流。Must-Right 針對必要事實,Easy-Wrong 針對模型常見的細節遺漏、幻覺或誤判;再配合 gated scoring,只要必要視覺事實出錯,就會被明顯扣分,而唔係被其他小分數平均掩蓋。
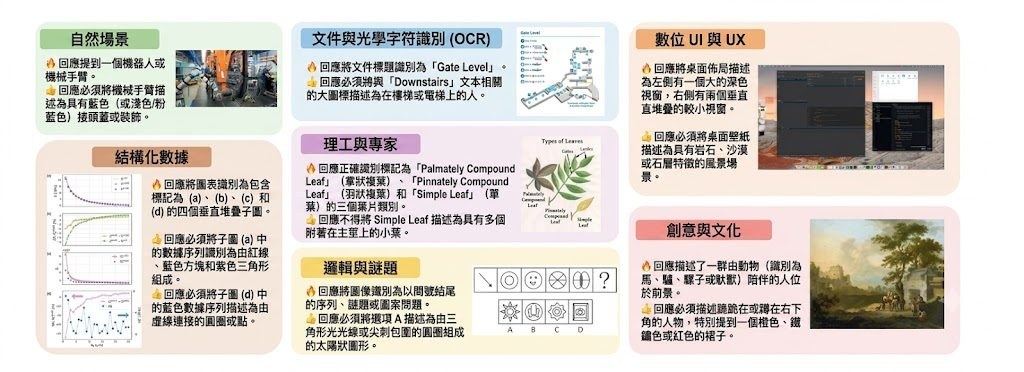
資料規模方面,項目提供 1,038 張 information-dense images,同超過 10,000 條 instance-specific rubrics,來源是用 Circular Peer-Review 建立的 Golden Captions,再蒸餾成評測規則。覆蓋範圍包括 natural scenes、OCR documents、GUIs、charts、STEM、logic puzzles 同 creative/cultural images,明顯偏向高資訊密度、容易出現感知失真的場景。
測試方式不算複雜:這個 GitHub 儲存庫主要提供 evaluation code 和 data,較適合研究團隊、模型開發者,或者需要比較多個 MLLMs 表現的人,把模型輸出的 captions 對照 rubric 計分。它不是部署給終端用家的應用程式,而是拿來驗證模型在圖像理解任務到底穩不穩;使用前亦要接受一點,這類更嚴格的評分會令模型成績比傳統 leaderboard 更難看,但診斷價值更高。
- 核心取向是由 holistic semantic matching 轉向 atomic auditing
- Must-Right 與 Easy-Wrong 直接對應關鍵事實與常犯細錯
- gated scoring 強調「關鍵錯一項就要反映出來」
- 資料集中在 GUIs、文件、圖表等高密度視覺任務
- 適合用來比較 20+ 主流 MLLMs 的感知可靠性,而唔只係比較平均分
項目指出模型經常能辨認零碎元素,卻未能同時滿足多個關鍵視覺約束,尤其在 GUIs、documents 同 structured charts 更明顯。README 與 supporting context 亦提到曾評測 20+ 主流 MLLMs,包括 GPT-5.5;不過這個儲存庫重點仍然是評測框架本身,而唔係推出新模型,所以較值得留意的是它怎樣暴露 perception brittleness,而不是單一排行榜名次。