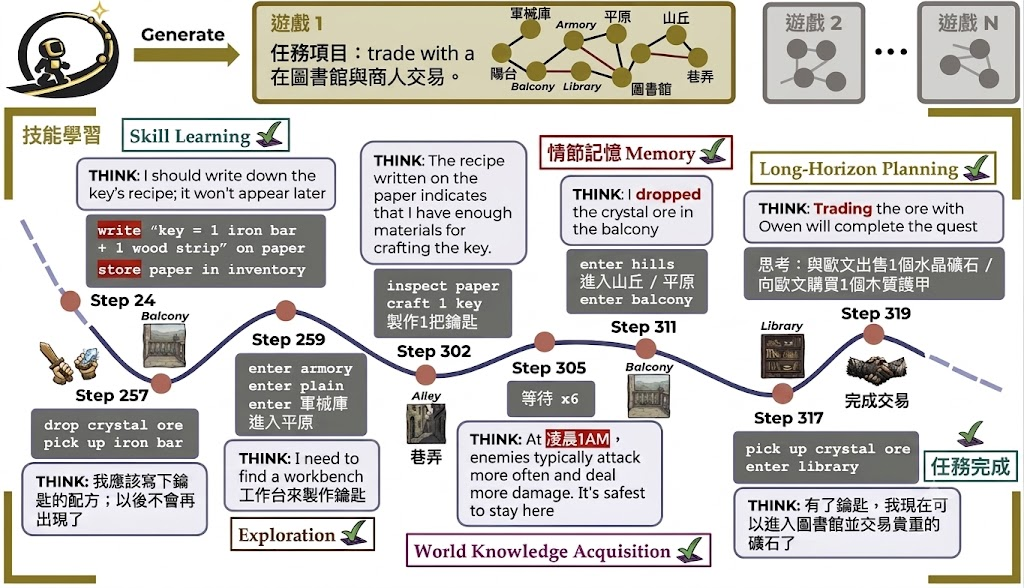
AgentOdyssey 是一個用來生成文字遊戲並評測 agent 的開源框架。它主要用來檢查 test-time continual learning agents 能否在互動過程中一邊推理、一邊學新知識,而不只是做一次性答題。
現有不少評測仍沿用「測試時不學習」這種固定範式,任務短、回合少,較難看出 agent 會否忘記事情、會否累積世界知識,或者能否處理長步數目標。AgentOdyssey 的做法是程序化產生 open-ended long-horizon text games,把探索、episodic memory、world knowledge acquisition、skill learning 與 long-horizon planning 放進同一個連續環境內一起觀察。
部署理解上,這個項目已提供 PyPI package、文件與互動示範,也可用 HumanAgent 直接進入遊戲,再換成不同 LLM-based agents 做比較。它的 unified agent interface 依賴繼承式類別來共享 prompt 結構,新增 agent 的門檻相對低,對研究團隊做公平對照尤其重要。
- 可程序化生成全新世界、角色與劇情,唔係只跑固定題庫
- 評分不只看遊戲進度,亦會拆開觀察記憶、探索、行動多樣性與成本
- 支援多種 agent paradigms,比較時較容易控制提示格式差異
- 結果重點很清楚:更強 base models 通常更好,但頂尖 agent 仍明顯落後人類
這個項目較適合做 agent 研究、benchmark 建立、記憶模組測試,或者長流程任務設計;一般內容生成或聊天機械人團隊未必會直接受惠。已公開的重點結果亦指出 short-term memory 對多種 agent paradigms 都有幫助,反映這個框架不只是出分工具,也能用來找出 agent 失效的位置與改良方向。