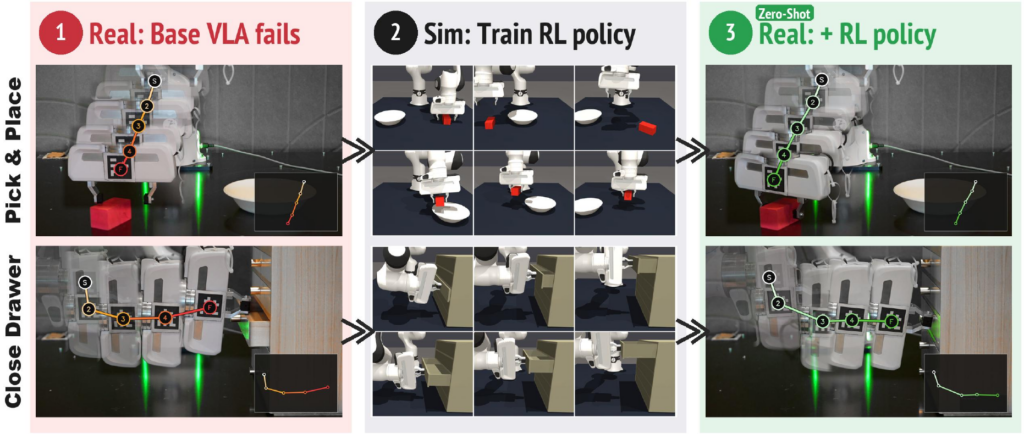
這是 Microsoft Research 的 Object-Centric Residual RL 方法。它的用途是為 Vision-Language-Action(VLA) 模型加入一層修正策略,減少機械人在真實操控中因細小誤差累積而失手的情況。
核心做法是把一個已凍結的 base VLA 保留不變,再額外疊加一個輕量 residual policy。這個 residual policy 完全在模擬環境訓練,輸入不是原始影像,而是 object-centric state、proprioception,以及 base VLA action,藉此避開常見的 visual sim-to-real gap,令策略可直接 zero-shot 轉移到真實機械人。
這個方法處理的是 imitation learning 常見的脆弱性:示範資料未覆蓋到的狀態一旦出現,誤差會一路放大。與直接微調 VLA、或在真實世界再做 reinforcement learning 相比,這個方法的差異在於只學「修正量」,而且訓練放在模擬中完成,成本與風險都較低。
- 保留 frozen base VLA,不用重訓整個模型
- residual policy 以物件中心狀態為主,減少依賴影像對齊
- 目標是 zero-shot sim-to-real enhancement
- 適合需要精準抓取、放置或接觸操作的機械人工作流
這類方法較適合關注 VLA、Robotic 與 sim-to-real transfer 的研究者和開發者。現有資料清楚交代方法方向與問題設定,但未提供完整安裝流程或操作步驟;評估部分可確認作者以真實機械人成功率改善作為重點,更多數值細節仍需參考原始論文。