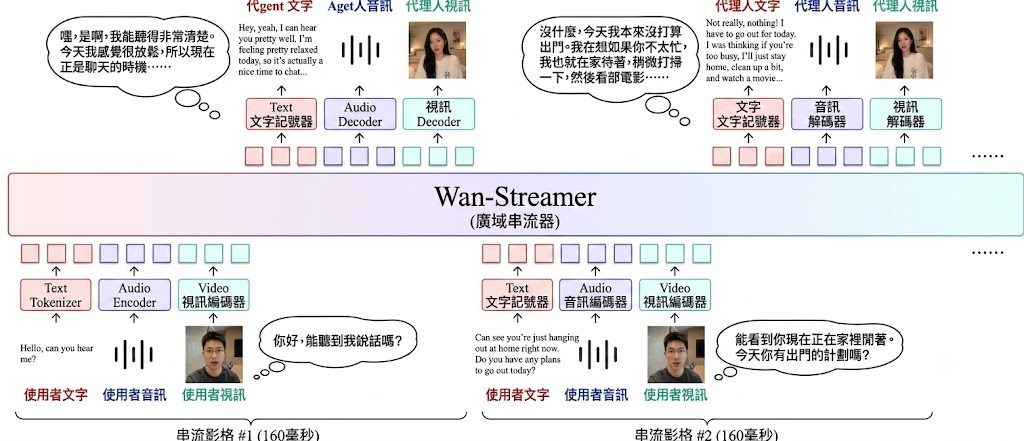
Wan Streamer v0.1 是一款由阿里巴巴(通義萬相/Wan 團隊)開發的原生流式端到端基礎模型,專為即時、低延遲、全雙工的音視頻互動而設計。它把語言、音訊、影像同時作為輸入與輸出,全部整合在單一 Transformer 之中,並以 block-causal attention 協調增量式生成。
現有即時互動系統普遍存在的延遲與不同步難題。純語音方案雖然回應快,但沒有可見的影像輸出;音視頻方案則多由 ASR、語言模型、TTS、動畫模組拼接而成,每個邊界都會疊加延遲,而且很少有系統公開端到端時延數字。Wan Streamer 把整個流程重新設計為可流式架構,包括因果編解碼器、block-causal attention、低延遲多模態 token 排程,在 25 fps 下最短流式單元可達 160 毫秒。
與常見做法的最大差異在於「端到端」與「同步影音輸出」。模型側延遲約 200 毫秒,加入 350 毫秒雙向網絡延遲後,總互動延遲約 550 毫秒,可支援亞秒級全雙工通訊。同時輸出語音與影片內容,而非分別由不同模組拼接,這是它最值得留意的特點。模型覆蓋聽、看、思考、說話、生成影像回應五種能力,適用於需要即時數字人、互動助理、虛擬陪伴等低延遲場景。
重點摘要:
- 由阿里 Wan/通義萬相團隊研發,定位為即時互動基礎模型
- 單一 Transformer 同時處理語音、影像、文字輸入與輸出
- 模型側延遲約 200 毫秒,總互動延遲約 550 毫秒
- 支援 25 fps 串流,最短流式單元 160 毫秒
- 與拼接式方案相比,延遲更低且影音輸出真正同步