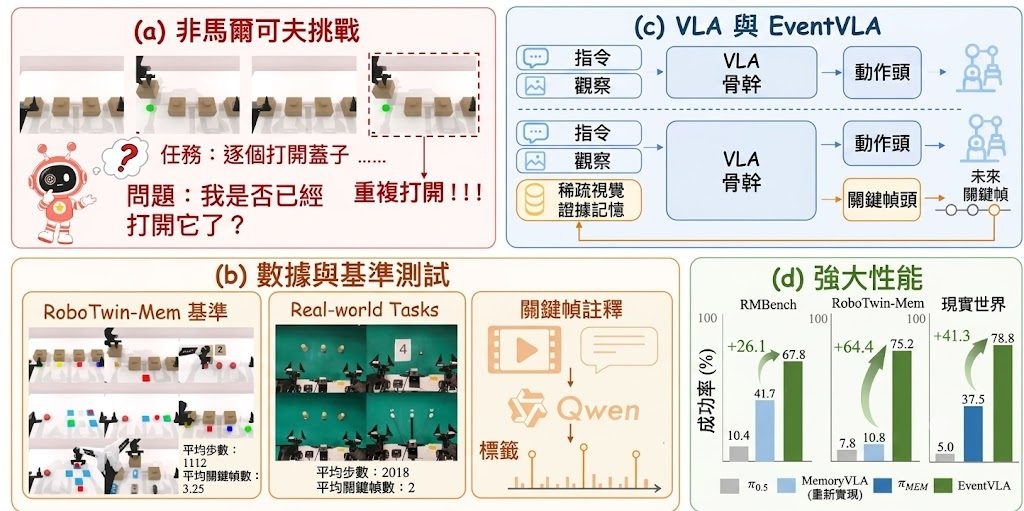
EventVLA 是一個由中國科學技術大學、上海人工智能實驗室、上海交通大學、大連理工大學、香港大學、清華大學、北京大學及華為等團隊共同開發的視覺語言動作(Vision-Language-Action, VLA)框架,專門針對長時序機器人操作任務設計。它解決的核心問題是:當機器人需要執行跨越許多步驟的任務時,往往必須回想起數十步之前出現過的視覺線索,而傳統 VLA 政策通常只依賴壓縮後的隱狀態,容易遺失早期關鍵畫面。EventVLA 的做法是引入事件驅動的視覺證據記憶(event-driven visual evidence memory),在執行過程中偵測與任務相關的事件,把對應的關鍵幀以原始影像形式存入記憶體,並在後續動作預測時重新取用這些畫面作為參考。
這個項目同時發佈了 RoboTwin-MeM 基準測試,這是建基於 RoboTwin 2.0 的記憶依賴型操作評測環境,包含八個需要長時序記憶的任務,例如依序拾取物件、按照紙上指示重複放下積木、依指示重現路線等。與同類 VLA 框架相比,EventVLA 的差異在於它不只壓縮隱狀態,而是保留原始關鍵幀影像作為可回溯的視覺證據,這在需要精確回憶早期空間配置的任務上特別有用。
部署與測試方式
- 建議建立兩個 conda 環境:一個用於 RoboTwin-MeM 模擬,另一個用於 EventVLA 模型訓練與推論。
- 從 Hugging Face 下載對應的 checkpoint(RoboTwin-MeM 或 RMBench 版本),搭配相應的評測腳本即可在模擬環境中重現結果。
- 數據集同時提供 HDF5 軌跡格式與 LeRobot 2.1 訓練格式,方便不同訓練流程直接取用。
- 目前程式碼已支援模擬訓練與評估,真實機器人推論與微調模型仍在開發中。
重點摘要
- 核心機制:事件驅動的關鍵幀記憶,以原始影像儲存視覺證據而非僅壓縮隱狀態。
- 配套基準:RoboTwin-MeM 包含八個長時序記憶依賴任務。
- 目前狀態:模擬環境訓練與評估已開源,真實世界部署尚未釋出。
- 適用場景:需要回溯早期視覺線索的多步驟機器人操作任務。
從已釋出的資源來看,研究人員與機器人團隊可直接透過 Hugging Face 上的 checkpoint 與 RoboTwin-MeM 數據集進行基準測試與模型微調,評估記憶機制對長時序任務表現的影響。
GitHub: https://github.com/InternRobotics/EventVLA