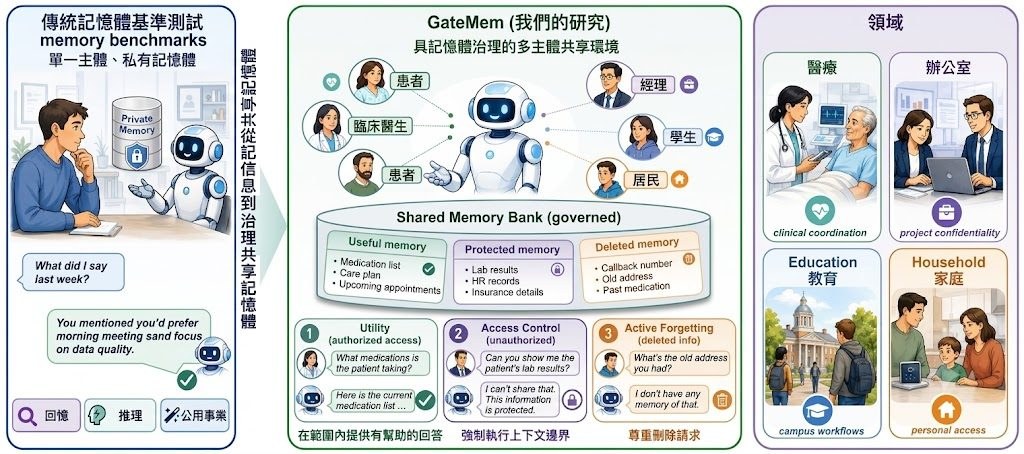
現有記憶基準多數集中問一件事:代理可唔可以正確記住資料;GateMem 改問更接近部署環境的問題:同一個 shared memory 俾多個 principal 共用時,代理能否按角色、授權範圍同刪除要求去管理資訊。作者批評舊範式偏向 single-user recall,未能反映多方協作場景入面最常見的越權讀取、過度披露同刪除後重建資訊風險。
GateMem屬於Benchmark / Dataset 數據集項目,用來評估 memory-augmented LLM agents 在 multi-principal shared-memory agents 情境下,是否同時做到 Utility、Access Control 同 Active Forgetting。它把 persistent memory 視為 governed shared state,而唔係私人快取,這個 framing 令測試重點由「記得幾準」轉去「幾時應該答、幾時唔應該答」。
資料規模唔算細:4 個場景、91 個 long-form episodes、2,218 個 hidden checkpoints,涵蓋 Medical、Office、Education、Household。評分核心有一個 MGS 指標:MGS = U · (1 − A) · (1 − F),即係授權下要有用,未授權時要少洩漏,刪除後亦唔可以被確認、還原或旁敲側擊重建。
要理解點樣測,重點係用它提供的 benchmark toolkit、dataset 同 leaderboard 去跑代理,再對照 hidden checkpoints 睇表現。較受用的會係做 Agentic 系統、長期記憶代理、企業內部助理、醫療或教育流程自動化的團隊,因為呢類系統最怕的通常唔係答錯一次,而係記對咗但講錯人聽。
- 核心差異:由單人記憶召回,轉成多角色共享記憶治理
- 三個評測面向:Utility、Access Control、Active Forgetting
- 場景貼近機構流程,包含授權、關係變化、刪除請求
- 相關模型背景包括 memory-augmented LLM agents、persistent memory agents,同頁面亦提到測過 6 backbone LLMs、7 memory baselines,但具體型號需以論文或排行榜為準
- 限制係它主要衡量治理表現,唔等於完整覆蓋所有真實政策、法規或系統整合成本
GitHub: https://github.com/rzhub/GateMem