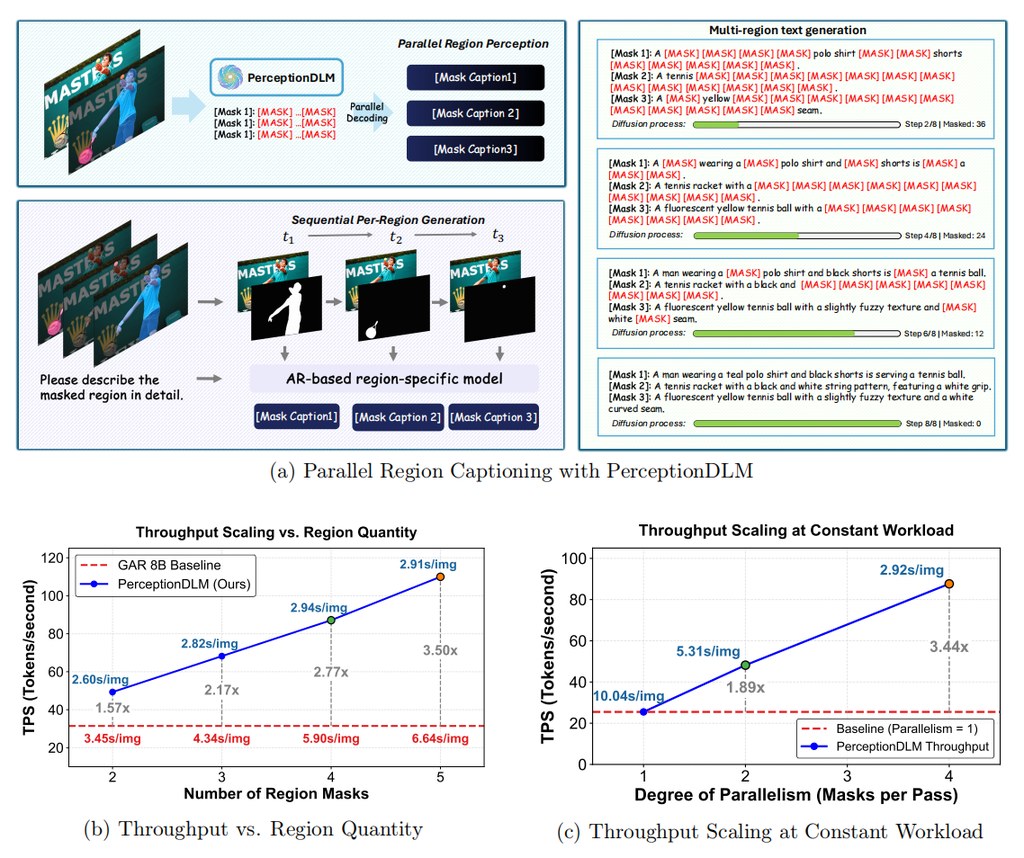
現時不少 Multimodal Large Language Models (MLLMs) 做區域描述時,仍然依賴 autoregressive (AR) 逐段生成:一張圖有幾多個 mask,就要逐個區域慢慢解讀。PerceptionDLM 提出的方向很明確,改用 Multimodal Diffusion Language Model,同一輪 denoising process 內同時輸出多個區域描述,目標是解決多區域感知在延遲上隨數量線性上升的問題。
這是一個偏向模型加基準測試的開源項目:核心是 PerceptionDLM 與 PerceptionDLM-Base,另加 ParaDLC-Bench、PerceptionDLM-Data 和 Bee / Honey 系列訓練資料配方。作者點名批評舊範式主要卡在 autoregressive region captioning,因此加入 efficient prompting 與 structured attention masking,讓平行生成不只停留在概念,而是落到 sequence level 同 token level。
從公開資料看,這個項目較適合以 Hugging Face 已釋出的模型、資料集與 evaluation suite 來理解和測試;想重現結果的人,亦可沿住訓練資料配方、Training 與 Evaluation 流程部署。對一般開發團隊而言,最有參考價值的不是安裝細節,而是它示範了 diffusion VLM 怎樣處理「多區域同時描述」這種以往較少由 DLM 承擔的任務。
- 單次 denoising pass 可同時描述多個 masked regions,官方稱在密集多區域情境可有最高 3.4× throughput speedup
- PerceptionDLM-Base 據稱在 16 個 multimodal benchmarks 之中,15 個勝過 LLaDA-V
- ParaDLC-Bench 不只看 caption quality,也把 inference efficiency 一併納入
- 已公開 code、model weights、training data recipe、evaluation suite,重現門檻比只放論文低
它較適合做視覺理解、圖像標註、自動資料整理,或者需要一次看多個區域的研究團隊。限制也很清楚:目前公開資訊主力強調 benchmark 與吞吐提升,對一般產品場景的記憶體需求、延遲分佈與部署成本仍要再看實測;相關模型則包括 PerceptionDLM、PerceptionDLM-Base,以及其 backbone LLaDA-8B-Instruct,對比對象則有 LLaDA-V。
GitHub: https://github.com/MSALab-PKU/PerceptionDLM
項目主頁: https://msalab-pku.github.io/projects/PerceptionDLM/index.html
項目: https://huggingface.co/collections/MSALab/perceptiondlm-model-zoo