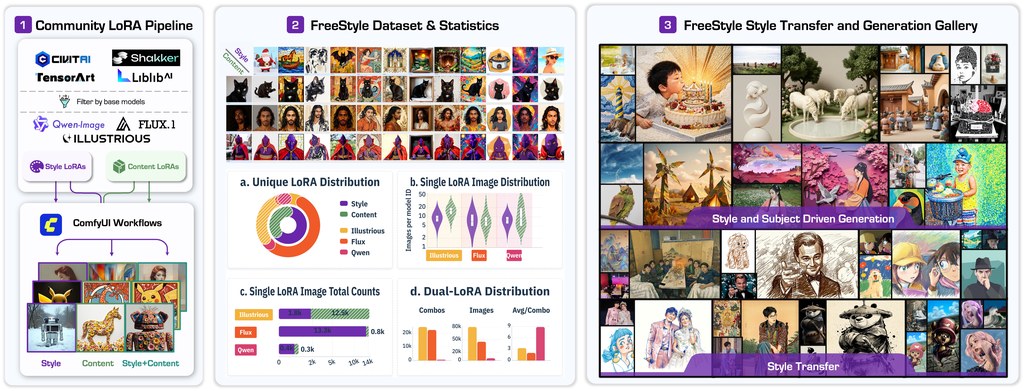
現時不少 style-reference 生成,只處理單一風格參考;至於 content + style dual-reference,常見難位是資料難整、風格長尾不足,兼且 style reference 容易把人物、物件等內容一併「滲」入結果。FreeStyle 把社群 LoRA 視為風格或內容概念的聚類中心,再配合自動生成與過濾流程,重組出可訓練的雙參考資料,連 benchmark 一起補上。
這不是單純模型,而是一個結合資料管線、benchmark 與 DiT-based model 的影像生成項目,目標是解決 SRef 與 CRef+SRef 兩類任務中,內容保持、風格對齊與 leakage suppression 很難同時兼顧的問題。文中提出 attention-level constraint,以及 RoPE low-frequency modulation,核心取向很清楚:寧可多做約束,也要壓住 style-reference content leakage。
資料規模是 FreeStyle 最有份量的部分。CRef+SRef dataset 提供 480K sequences,涵蓋 1,704 種 styles;SRef dataset 則有 619,302 sequences、622 種 styles。評測亦不只看靚唔靚,還加入 CSD、OneIG、DINOv2、CAS、CLIP-T、aesthetic predictors 及 VLM-as-judge,將 style similarity、content preservation、instruction following 同 leakage rejection 分開量度。
想理解怎樣測試這個項目,較合理的做法是分三層看:先用公開 dataset 與 benchmark 檢查資料結構;再看 repo 提供的 LoRA metadata 與 ComfyUI workflows,理解 triplet 怎樣生成與驗證;最後才研究 checkpoint 表現。它較適合研究團隊、做可控生圖的產品組,或者本身已在用 FLUX、Qwen、Illustrious 生態的人。
- 把 Civitai、TensorArt、Liblib 的社群 LoRA 變成可用訓練訊號
- 同時覆蓋 SRef 與 CRef+SRef,而非只做單一風格參考
- 重點不是單純追求風格像,而是壓低內容洩漏
- 提供 dataset、benchmark、workflow、checkpoint,便於重現整個流程
相關模型與基礎生態包括 DiT-based model、FLUX、Illustrious、Qwen,以及資料生成用的 ComfyUI workflow。若你關心的是商用穩定性,仍要留意它相當依賴社群 LoRA 品質與過濾流程;作者亦有講明,原始 LoRA 權重本身未必會隨項目再分發。