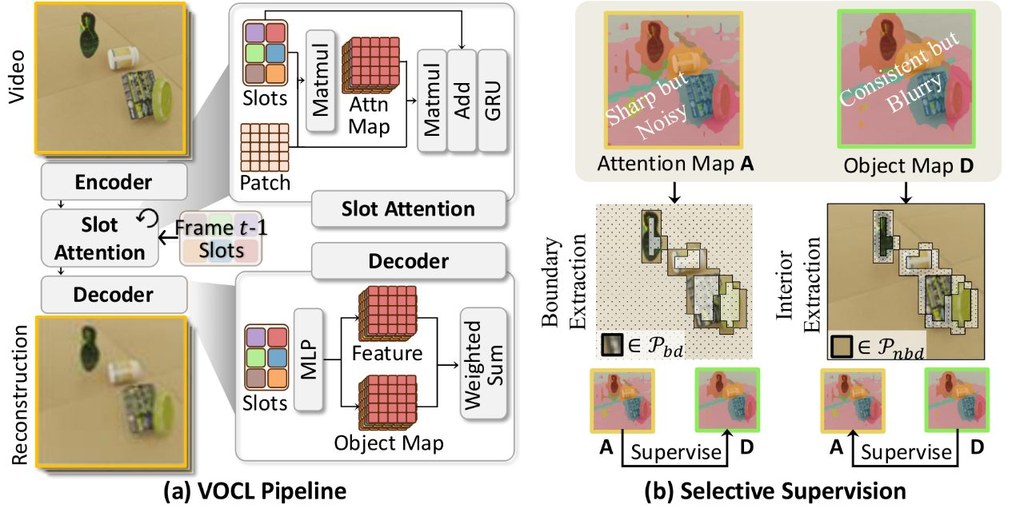
現有的 video object-centric learning(VOCL)多數沿用 slot-based frameworks,通常建基於 reconstruction-driven encoder–decoder architectures:encoder 產生 attention maps,decoder 產生 object maps,再嘗試把兩者對齊。近年的 dense alignment strategy 會對所有 spatio-temporal patches 做 contrastive learning,但這種全對全對齊會把 encoder 的雜訊和 decoder 的模糊邊界一併放大,計算量亦會升到 quadratic complexity,影片一長就更難擴展。
SSync(Selective Synergistic Learning)屬於一個可插入現有流程的 PyTorch 學習模組,目標是改善影片中的物件分解質素。它不是強迫所有 patch 全面一致,而是只挑選較可信的訊號做 mutual-distillation:用 encoder 幫手修邊界,用 decoder 清理物件內部雜訊,方向相當明確。
這項目把「全部都對齊」改成 selective distillation,並透過 pseudo-labeling 把成本降到 linear complexity。作者亦加入 transitive pseudo-label merging,處理 slot redundancy,將時序上反覆重疊的 slots 合併,減少模型把同一物件拆成多份的偏差。
如果你本身有研究 Slot Attention、影片分解、無監督物件發現,這項工作相當值得細看;如果你只是想快速試概念,亦可直接留意作者提供的 PyTorch implementation、Hugging Face 權重和 project page。它屬於 plug-and-play module,較適合已有 VOCL 基礎模型的人接入比較,而不是給完全零基礎讀者當成獨立應用程式。
- 核心問題:dense alignment strategy 計算昂貴,亦會傳播 encoder 與 decoder 各自的錯誤
- 核心方法:Selective Synergistic Learning 只蒸餾可靠線索,分開處理 boundary refinement 與 interior denoising
- 結構補強:加入 transitive pseudo-label merging,減少 slot redundancy
- 論文聲稱:可提升 decomposition quality,並對 slot configurations 有較強 robustness
- 相關技術詞:VOCL、slot-based frameworks、Slot Attention、mutual-distillation、pseudo-labeling
整體來看,SSync 的價值不在於另起爐灶,而是在既有 slot-based video learning 範式上,直接指出 dense patch alignment 的兩個痛點:錯誤傳播與計算擴張。對研究型讀者而言,這比單純再堆模型容量更有意思;對工程導向團隊而言,它也提供了一個較容易插入現有項目的改良方向。