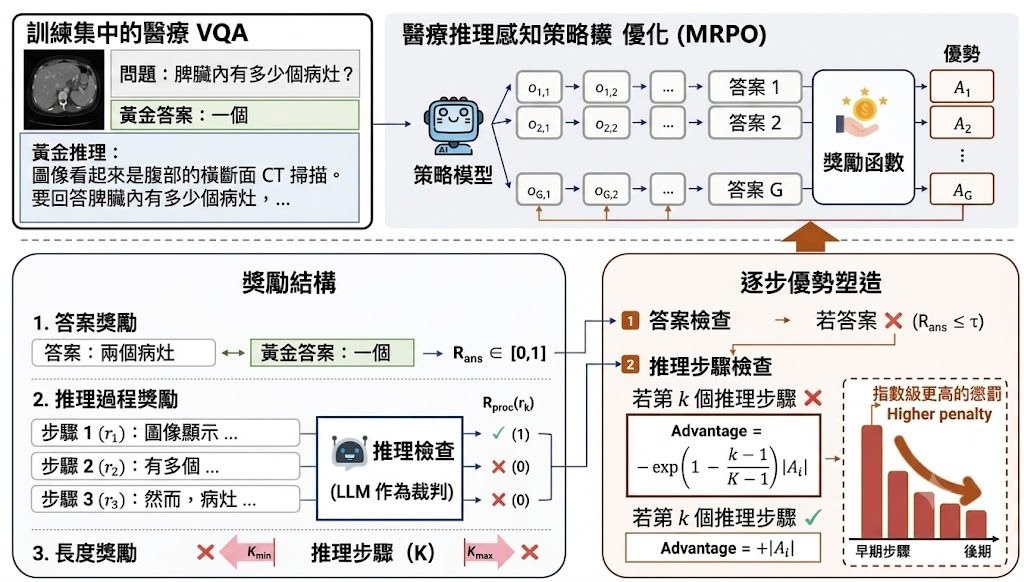
MRPO 是一個用於醫療多模態推理的強化學習框架(reinforcement learning framework)。它要解決的問題不是單純答對與否,而是醫療 VQA 過程中推理鏈一早出錯,之後一路連鎖失誤,令最後答案偏離。
現有 post-training 做法多數偏向 outcome-centric,主要看 final answer correctness 或 sequence-level preferences。作者認為這種範式的問題是 sparse credit assignment,模型知道答錯,卻未必知道究竟由哪一步開始失準;MRPO 因而改寫 GRPO-style advantages,結合 answer-level reward 與 step-wise process rewards,並在最終答案錯誤時,對較早出現的 invalid steps 給予更大懲罰。
這個設計的取向很明確:它不是只罰錯答案,而是重新分配學習訊號,優先修正最早發生的推理錯誤,避免 failure cascades 擴大。README 提到,MRPO 在三個 multimodal LLM backbones 上都優於 standard GRPO 與另一個近期 RL baseline;在 Qwen3-VL-8B-Instruct 上,更以只用 13K training samples 超過較大的醫療 MLLMs,例如 HuatuoGPT-Vision-34B,分數高出 2.79。
- 核心方法:以 answer-level reward 加 step-wise process rewards 重整 GRPO-style advantages
- 主要差異:重點放在 first failure,而不是只看最後有冇答中
- 已公布內容:完整 reinforcement learning recipe、code、datasets 同 infrastructure
- 可重現方式:項目提供環境腳本、資料下載與前處理流程,訓練資料包含 image、problem、solution 欄位
- 相關模型:Qwen3-VL-8B-Instruct、HuatuoGPT-Vision-34B,以及 README 提及的另外兩個 multimodal LLM backbones
量化結果最值得留意的是推理質素分析。MRPO 將 early-stage reasoning failures 由 64.0% 降到 13.0%,反映它不只是把答案分數推高,而是令中途推理較少一開始就偏離;這對醫療影像問答尤其重要,因為錯誤往往不是出在最後一句,而是前面觀察與判斷已經失焦。
這個項目較適合研究醫療 AI、醫療影像問答、multimodal reasoning post-training 的團隊參考,也適合想比較 RL 訓練配方差異的人閱讀與重現。它現階段更接近研究原型與訓練方法展示,不是即裝即用的臨床產品;重點價值在於,它把「模型哪一步開始諗錯」正式納入訓練訊號,為醫療 MLLMs 提供一條比只看最終答案更細緻的優化方向。