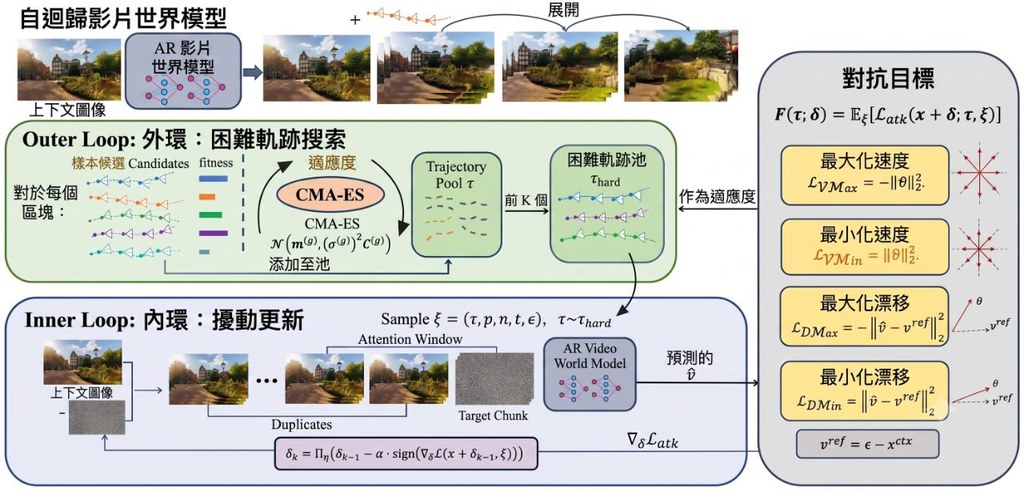
視覺世界模型(Visual World Models, VWMs)能從一張起始圖片,根據使用者動作序列合成出互動式的未來影片。現有做法多數沿用文字生成圖像或文字生成影片的對抗攻擊範式,但這類方法通常假設有固定的參考輸出或可取得的未來幀標籤。BadWorld 的作者指出,攻擊 VWMs 面對兩道根本限制:攻擊者根本拿不到真實的未來影片當作監督訊號,也無法預測使用者接下來會輸入什麼動作,因此傳統攻擊範式無法直接套用。
為此,團隊提出 BadWorld 框架,屬於一種安全研究工具,專門用來壓力測試自回歸式世界模型的時序穩健性。它繞過「需要未來監督」這道牆,採用自監督的速度擾動攻擊(self-supervised velocity attack),直接破壞模型早期的去噪動力學;同時,為了讓攻擊在未知動作下仍然有效,設計了軌跡自適應雙層優化(trajectory-adaptive bi-level optimization),主動挖掘困難的動作序列以鍛造「對動作無感」的擾動。
從測試結果來看,視覺上幾乎無法分辨的對抗圖片,能可靠觸發後續推演的災難性退化,出現去噪不完全、結構崩塌、控制訊號前後不一致等現象。這些發現對準備把世界模型應用於自動駕駛、機器人等安全關鍵場景的開發者是一記警鐘,同時也提供了一種可操作的隱私保護機制。
如果想自行驗證,可以針對 Matrix-Game-2.0 與 Astra 兩款開源世界模型測試。Matrix-Game-2.0 需約 32GB 顯示記憶體,Astra 則需 80GB,環境需要搭配 FlashAttention 與 NVIDIA Apex 等加速庫,並從 Hugging Face 下載預訓練權重。
- 屬於安全研究工具,針對視覺世界模型做對抗壓力測試。
- 突破傳統攻擊需「未來監督」的限制,採自監督速度擾動。
- 透過軌跡自適應雙層優化,鍛造對未知動作仍有效的擾動。
- 已在 Matrix-Game-2.0 與 Astra 上展示結構性崩潰。
- 對自駕、機器人、遊戲模擬等安全關鍵部署具警示意義。