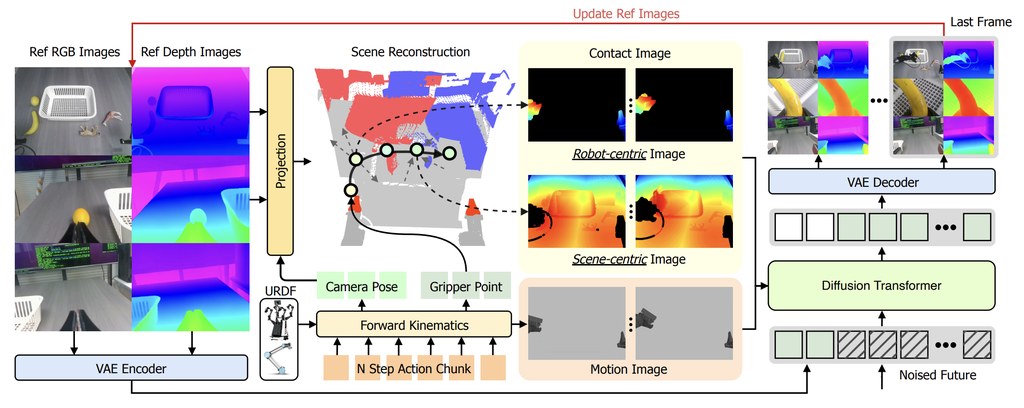
現時不少 action-conditioned video models 會把未來動作壓成 compact vectors,再經 learned conditioning modules 交給模型處理;作者認為這種做法要模型自行猜測細微空間後果,遇到 real manipulation 時,幾厘米差距已足以改變接觸、物件移動與任務成敗。iMaC 屬於世界模型與影片生成模型,核心是把 future joint actions 轉成 image-like controls,減少「動作有輸入,但空間關係表達不足」的問題。
這個項目的方法相當具體:先利用 robot URDF 與 forward kinematics,渲染 future robot-observation control videos,也就是 motion images;之後再加入 depth 作為輔助訊號,配合 3D pointclouds 建立 two-stream geometry controls,也就是 contact images。舊範式主要靠抽象向量條件化,iMaC 則把「未來機械臂會出現在哪裡、如何接近場景」直接變成可見控制,這是它最清晰的技術分野。
GitHub 儲存庫提供 training、preprocessing 與 inference code,覆蓋 RND-mix stage-one、stage-two,以及 WorldArena 三條流程。想試這個項目的人,會先由資料前處理、depth 與 3D condition 建立開始,再跑 validation inference 看生成影片是否跟動作一致;若本身做 robotic policy evaluation,還可以接到 WorldArena 或 online RND evaluation 場景。
- 把 actions 轉成 motion images 與 contact images,空間條件更明確
- 用 depth encoding 和 3D pointclouds 強化 robot-scene 幾何理解
- 加入 training-time rollout strategy,目標是支援更長時序生成並減少 exposure bias
- 儲存庫同時涵蓋訓練、前處理、推論,不只是論文展示模型
- 相關組件包括 Wan transformer variants、Diffusion inference pipelines、RobotWin 2.0、WorldArena
性能方面,論文指出它在八個長時序真實機械人操作任務中,world-model success estimates 與真實 policy performance 呈強正相關。這個結果的價值不在於取代真機測試,而是在正式落機前,先用生成式 world model 篩選 policy checkpoints;對研究 embodied evaluation、robotics 與世界模型的人來說,iMaC 屬於相當值得跟進的一個方向。
GitHub: https://github.com/imac-wm/iMac