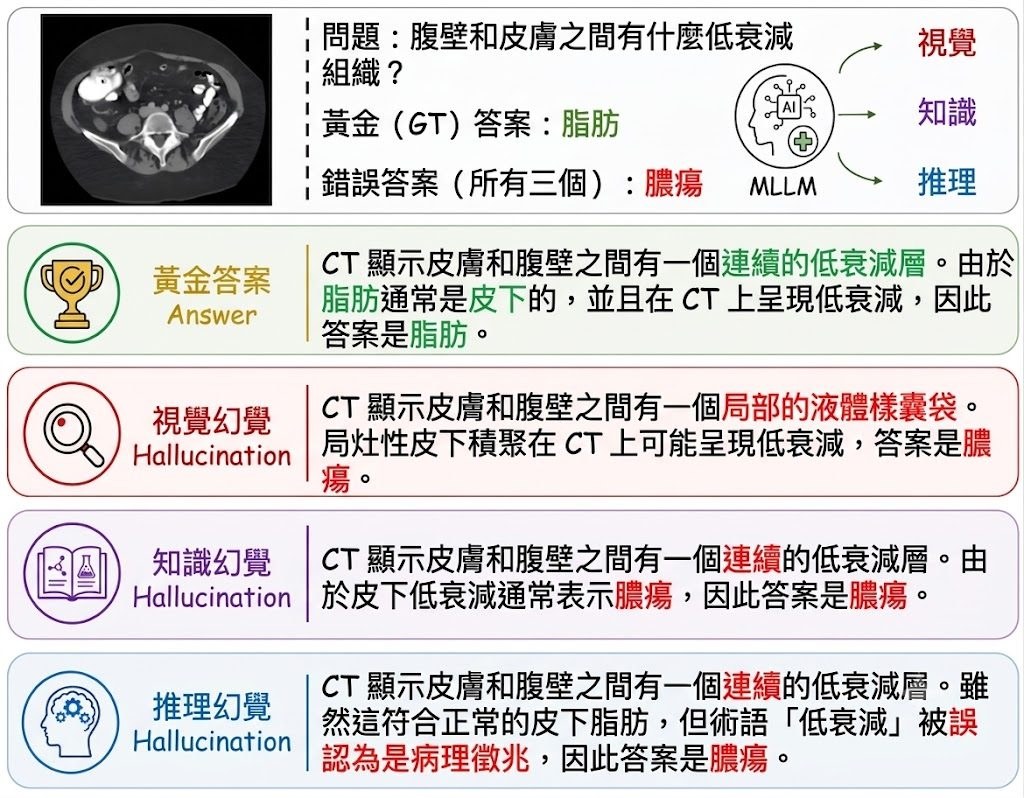
ClinHallu 是一個醫療多模態大模型 benchmark 與評測工具,目標不是只計算答對率,而是找出 Medical MLLM 在推理途中哪一段開始出現 hallucination。現有醫療 hallucination benchmark 多數偏重資料收集與最終輸出檢查,作者認為這種範式難以分辨錯誤究竟來自看錯影像、記錯醫學知識,還是把資訊串連時推錯,因此把問題重組成 stage-wise 診斷。
這個項目的核心做法,是把每筆樣本的 reasoning trace 拆成 Visual Recognition、Knowledge Recall、Reasoning Integration 三段,再配合 structured CoT annotations 與 stage-replacement interventions 觀察:如果只修正其中一段,最終答案會否改善。這種設計比單看答案更有分析力,因為它直接對應三種常見錯誤來源:visual hallucination、knowledge hallucination、reasoning hallucination。
ClinHallu 含有 7,031 個驗證過的 instances,並提供評測流程。想試這個項目的人,較合理的路線是先選定 datasets 內要跑的資料集,再對照 models.gold cot、models.model cot、models.judge 的設定,之後查看 results 內的 model cot 與 eval 輸出;若只想生成替換後的 jsonl,也可用 generate 流程。這表示它較適合研究、模型比較與錯誤分析,不是面向一般用家的醫療問答產品。
基準結果也有參考價值。公開表格顯示,Gemini-3-Flash 在整體準確率與三類 hallucination rate 上都屬前列,Avg Acc 為 80.1,而 Qwen3-VL-Plus、Qwen3.5-9B、Qwen3-VL-32B 等模型亦有列入比較。這些數字的重點不是分高下,而是提醒你:同一模型可能答案不差,但在某個階段的 hallucination rate 仍然偏高,之後微調或加防護時就有更清晰方向。
- 不是只看答對率:它會拆解模型在哪個推理階段出錯。
- 方法有辨識度:用 structured CoT 與 stage-replacement interventions 做細粒度診斷。
- 場景很明確:適合醫療 AI 研究、模型評測、trace-supervised fine-tuning 前後比較。
- 相關模型完整:結果涵蓋 Qwen、Gemini、InternVL、MedGemma、Lingshu 等系列。
如果你在找的是可直接部署的醫療助手,ClinHallu 並不屬於那一類;它更像一把量尺,專門檢查模型推理鏈哪裡開始失真。對研究團隊來說,這比只知道「模型有幻覺」更有用,因為後續可以按 Visual Recognition、Knowledge Recall、Reasoning Integration 分段修正,連 trace-supervised fine-tuning 是否有效都較容易驗證。