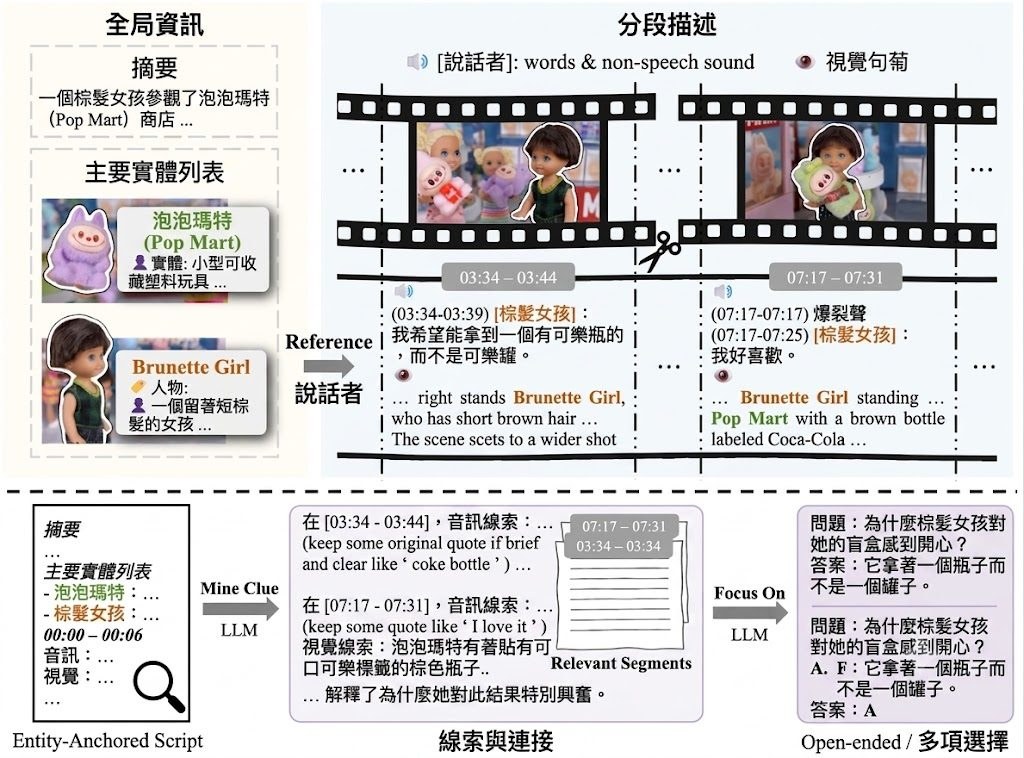
現時不少影音問答資料建立流程,普遍沿用「video-caption-QA」範式:先把影片切成短片段,再分開寫視覺與音訊描述,最後生成 QA。論文作者認為這種做法容易出現 modality bias、temporal misalignment,同一角色在不同片段亦可能描述不一致,令問題多數只圍繞局部事件,難以考驗長時間跨度的 audio-visual reasoning。
OmniVideo-100K 是一個 Dataset 數據集,目標是為 Multimodal Large Language Models (MLLMs) 提供較完整的影音推理訓練材料。它提出兩個核心機制:Entity-Anchored Video Scripting 先把原始影片整理成結構化 script,包括摘要、主要實體清單,以及帶時間戳的分段音畫描述;Clue-Guided QA Generation 則先抽取跨片段、跨模態線索,再生成較複雜的問答。
這種設計的關鍵,不在於題目數量大,而在於先整理證據鏈再出題。對比舊方法把長文本理解和 QA 合併成一步,OmniVideo-100K 把線索挖掘獨立出來,較有機會產生涉及因果、未來預測與假設推理的題目,而不只是問畫面中「見到乜」。
如果你想測試這個項目,可以先留意 Hugging Face 上的 OmniVideo-100K 與人手驗證的 OmniVideo-Test,看看資料結構是否適合自己的訓練流程;做研究的人則可直接比較模型在外部 benchmark 的變化。論文提到,VITA-1.5、Qwen2.5-Omni-7B、Qwen3-Omni-30B 經此資料集微調後,在 OmniVideo-Test 最多提升 20.59%,在 Daily-Omni、JointAVBench 也有最多 12.64% 增幅,同時盡量保留在 Video-MME 這類一般影片 benchmark 的能力。
- 針對舊式「video-caption-QA」流程的三個痛點:modality bias、temporal misalignment、敘事不連貫
- 用 structured scripts 加 entity list,補回跨片段指代一致性與聲音來源對應
- 任務覆蓋 10 類,包括 FGP、STD、CU、CP、SA、ESO、SM、CR、FP、HR
- 適合做影音理解、跨模態推理、指令微調資料研究的人參考
- 相關模型包括 VITA-1.5、Qwen2.5-Omni-7B、Qwen3-Omni-30B
整體來看,這個項目的價值在於它不只新增一批資料,而是重寫影音 QA 資料的組織方法。若你關心的不是單張畫面問答,而是影片內角色、聲音、事件先後與推論之間的連結,OmniVideo-100K 會比一般自動合成資料集更有研究參考價值。