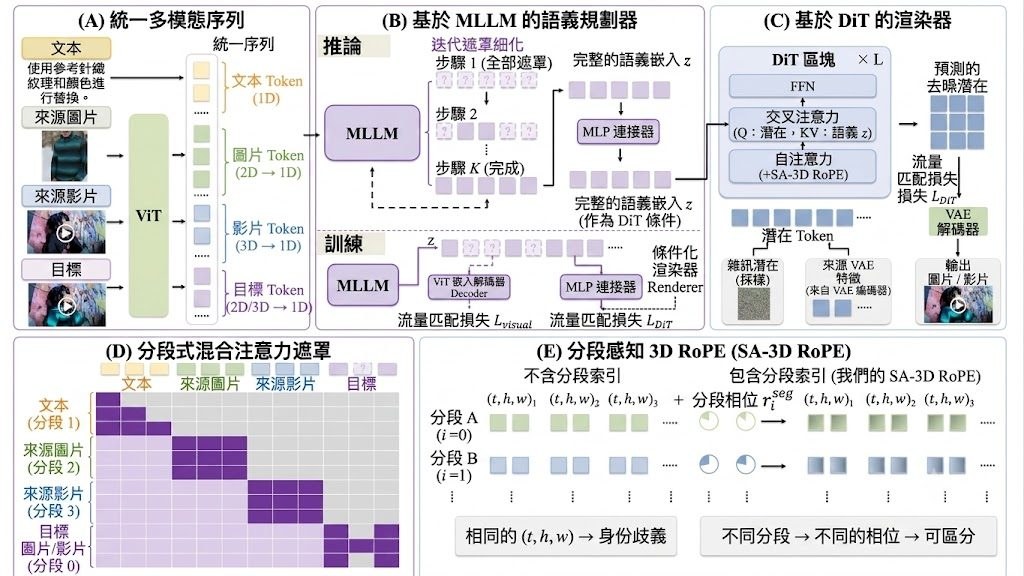
Bernini 是一個影片生成與編輯框架,核心是把 MLLM-based semantic planner 與 DiT-based renderer 組合起來,處理一般影片擴散模型常見的內容漂移、指令跟從不穩定,以及長片段規劃鬆散等問題。從定位看,它不是單純再堆大模型,而是先做語意規劃,再交由生成器落實畫面。
這個項目的關鍵想法,在於「Latent Semantic Planning」:先在潛在空間安排語意,再做 video diffusion。對非研究背景讀者來說,可以理解為先寫分鏡草稿,再逐格畫面化,這比直接由文字一步到位生成影片,更有機會保持故事連貫和編輯意圖一致。
如果想試,較合理的切入點是影片編輯任務,例如風格轉換、字幕或水印移除、局部修改,再觀察輸出有沒有跟足指令。倉庫列出的環境偏高階,建議準備 CUDA 12.4、Python 3.11.2,以及 torch==2.5.1+cu124、diffusers==0.35.2、accelerate==0.34.2、transformers==4.57.3;若有 H100、H800、H200 可配合 FlashAttention-3,其他 CUDA GPU 則退回 FlashAttention-2 或 PyTorch SDPA。
Bernini 在 video editing 的表現進入部分主流 closed-source commercial models 的第一梯隊,評分來自其自建 arena,以人工盲選、Bradley-Terry score 及 pairwise win-rate matrix 彙整。這類結果有參考價值,但暫時主要反映編輯場景;若你關心更複雜的人物生成,官方也提到 1.3B 的 Bernini-R 在簡單任務接近 14B 版本,面對複雜任務仍有差距。

- 核心組成是 MLLM-based semantic planner + DiT-based renderer
- 已公開 Bernini-R 權重,包含 1.3B 版本
- 適合研究影片生成、影片編輯流程,或想比較規劃式生成方法的人
- 硬件門檻偏高,Multi-GPU sequence parallel 亦需要 Open-VeOmni
- 相關模型可先留意 Bernini-R-1.3B-Diffusers,以及文中提到的 14B 變體
整體來看,Bernini 最有價值的地方不是「再一個影片模型」,而是把規劃與渲染拆開處理,令可控性成為主要賣點。若你想找可直接在普通電腦輕鬆跑的項目,它未必合適;但如果你重視研究方向、編輯質素與系統設計,這個項目相當值得細看。