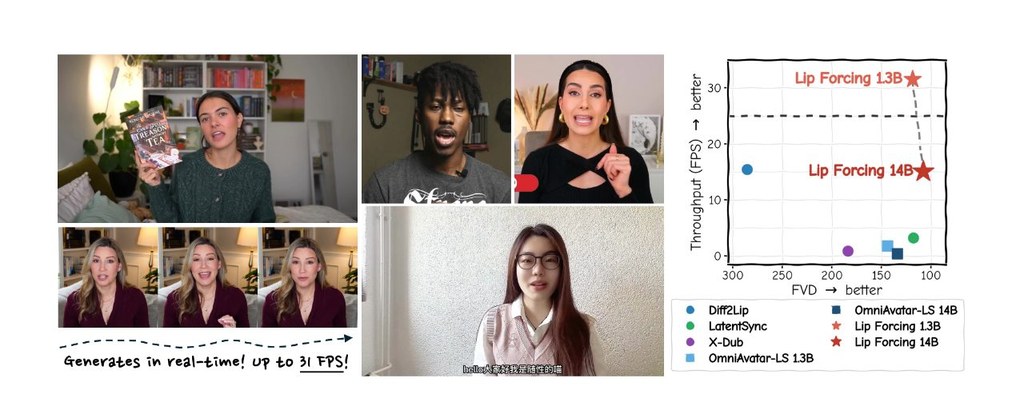
Lip Forcing 是一個針對 video-to-video(V2V)lip synchronization 的研究項目,重點是把 diffusion 模型原本昂貴的推理流程,大幅壓縮到適合即時串流使用。它希望在保留人物身份、頭部姿勢與背景一致性的同時,令口型更準確貼合目標音訊。
現有 diffusion-based 唇形同步方法畫質和聲畫對齊表現不錯,但通常要看完整段影片、再經過很多次 denoising steps,速度和延遲都難以配合直播翻譯、virtual avatars、interactive agents 這類場景。Lip Forcing 改用 autoregressive diffusion,把影片分段逐塊生成,並把 50-step teacher 壓縮成 two-step streaming student,減少計算負擔。
對 lip-sync 任務,本身不是單純套用通用加速技巧。作者指出 CFG 會在 reference fidelity 與 synchronization 之間出現取捨,並據此設計出 Sync-Window DMD、two-step inference schedule,以及以 SyncNet 為基礎的 reward,目標是在少步數下仍維持可用的唇形同步效果。
兩個 student 模型都由 14B teacher 蒸餾而來。1.3B student 可達 31 FPS,速度比同規模 bidirectional model 快 17.6 倍;14B student 則比 teacher 快 39.8 倍,並維持相近的 reference fidelity。兩個版本的 time-to-first-frame 都低於 1 毫秒,顯示它特別適合低延遲串流情境。
- 支援即時串流,最高可達 31 FPS
- 每個 chunk 只需 two denoising steps,毋須 inference-time CFG
- 採用 autoregressive diffusion,降低全序列注意力帶來的成本
- 針對 lip synchronization 設計蒸餾方法,不是一般加速改裝
- 適合 live translation、virtual avatars、interactive agents 等場景
如果你關注的是即時嘴型同步、低延遲影片生成,或想了解 few-step autoregressive diffusion 如何落地到影音任務,這個項目相當有參考價值。文中可確認引用與比較的技術脈絡包括 Computer-use agents、CUAs、LoRA、OSWorld 以外的影音生成方向;就本頁內容可明確列出的模型,主要是 14B audio-conditioned bidirectional video diffusion teacher、1.3B student、14B student,以及 SyncNet。