這個開源項目是一套AI 代理人評測基準,專門用來量度 Computer-use agents(CUAs)在長時間、跨步驟的真實工作流程中表現如何。它的設計目標是讓業界能用同一把尺,去比較 Claude Code、Codex、Openclaw 等不同代理人在真實場景下的能力差距,而不再停留在簡單的問答測試。
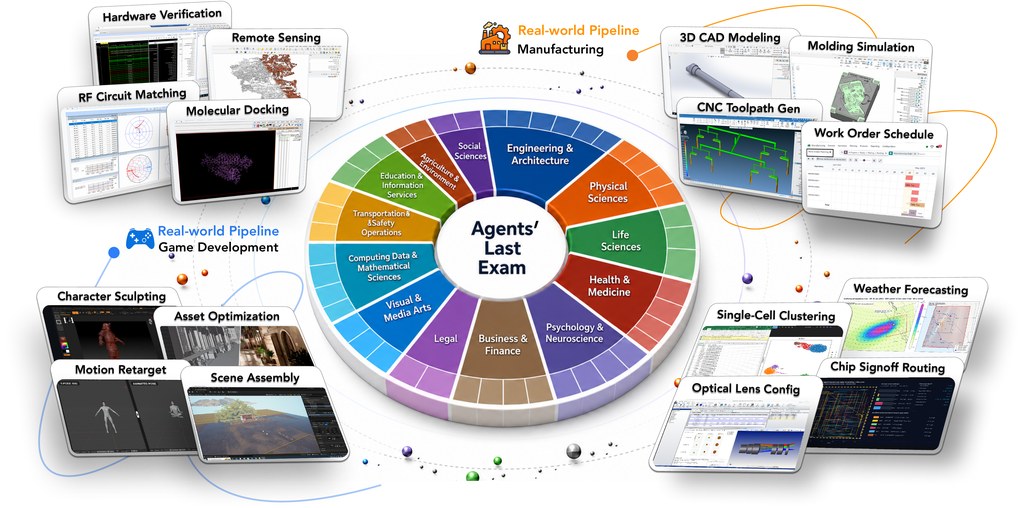
ALE 與坊間常見的排行榜最大分別,在於它把任務對齊到美國 O*NET / SOC 2018 職業分類,涵蓋 55 個非實體行業,例如動畫、工程製造、建築設計與神經影像分析等。基準的題目並非由研究員憑空設計,而是由 300 多位業界專家收集並驗證,因此每一條任務都貼近真實工作場景,而且配有隱藏參考答案與確定性評分機制,杜絕模型「走旁門左道」蒙混過關。
在技術架構上,評測框架由三部分組成:代理執行環境(harness) 負責驅動底層基礎模型;虛擬沙箱(sandbox) 模擬真實作業系統環境;任務單元(task) 則以可執行方式描述一項專業工作。目前公開的 150 條任務屬於 1,500 題以上語料庫的子集,整個項目正在朝 5,000 題目標推進。評測時,框架會在雲端建立沙箱、讓代理人完成任務,再以確定性評分器評分,過程全自動化。
測試前需要先在 Google Cloud 完成一次性設定(約 10 分鐘,現有 $300 美元免費額度足以應付),之後即可在自家模型上執行 hello-world 任務以熟悉流程,進一步換成正式任務。這個項目適合 AI 代理人開發者、企業採購團隊、學術研究者,以及任何想用客觀分數比較不同 CUA 表現的人。
- 代理評測基準:專為 Computer-use agents 設計的真實工作流程測試。
- 行業覆蓋廣:對齊 O*NET / SOC 2018,涵蓋 55 個行業,公開 150 條任務。
- 結果可驗證:採用隱藏參考答案與確定性評分器,公平且可重現。
- 雲端沙箱環境:在 Google Cloud 內建立虛擬機重現真實作業流程。
- 社群共創:由柏克萊 RDI 與 300 多位業界專家共同維護。