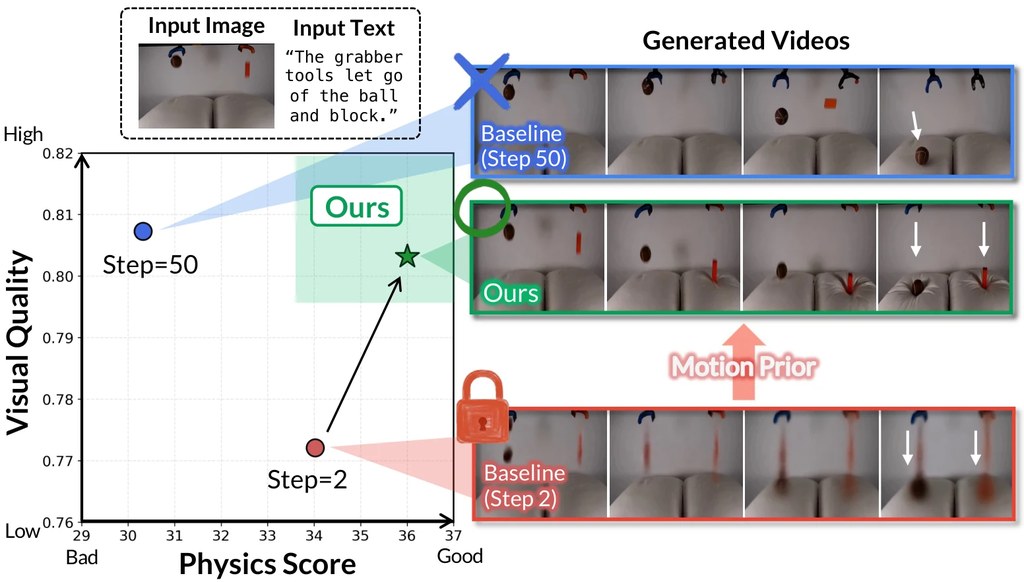
PhaseLock 是一個針對 Image-to-Video diffusion models 的方法,重點是修正影片生成中常見的物理錯誤。主要是針對 inference-time method / sampling strategy。模型在完整 50 步去噪時雖然畫面更細緻,但動作反而可能偏離物理規律;相對地,只做 2 步去噪時,動作先驗更可信,只是質感較粗糙。
項目的核心做法是兩階段流程,而且不需要額外訓練。它會先用 2 步去噪抽出 motion prior,文中以 Δ phys 表示,再在 50 步完整生成期間以 Latent Delta Guidance 重新注入,目標是在高保真畫面中保留較合理的動態結果。
例子很直觀,例如非磁性的網球不應被帶磁的籃子吸起。基線結果會產生違反常識的動作,PhaseLock 則較能維持物件應有的移動方式。這類情況很適合用於需要基本物理合理性的影片生成項目,例如物件互動、掉落、抓取或接觸場景。
重點可歸納為:
– 以 training-free 方式改善影片中的物理一致性
– 發現 2-step generation 的 physics 可能比 50-step output 更好
– 透過 Latent Delta Guidance 把早期 motion prior 鎖回最終結果
– 報告指出 physical consistency 平均提升 +6.2 points
– 額外成本相對有限,約 1.06× time、1.02× memory
如果你本身已在用影片擴散模型,這個項目的使用概念不算複雜:先跑短步數結果取出動作訊號,再配合完整步數生成。從現有內容看,PhaseLock 的價值不在於更換主模型,而是在同一模型之上補回被後期去噪「磨走」的動作先驗。文中提到測試用的模型包括 Wan 2.1。