大型語言模型(LLMs)會背誦訓練資料,但現有的記憶性評估大多只關心「能不能逼它說出來」,而忽略了「它在一般使用下到底會不會自己講」。PropMe 正是針對這個落差而設計的傾向感知(propensity-aware)評估框架,它把前綴式的能力攻擊(prefix-style capability attacks)與日常、非對抗的生成結果並列比較,計算出模型在真實情境下洩漏訓練資料的傾向。
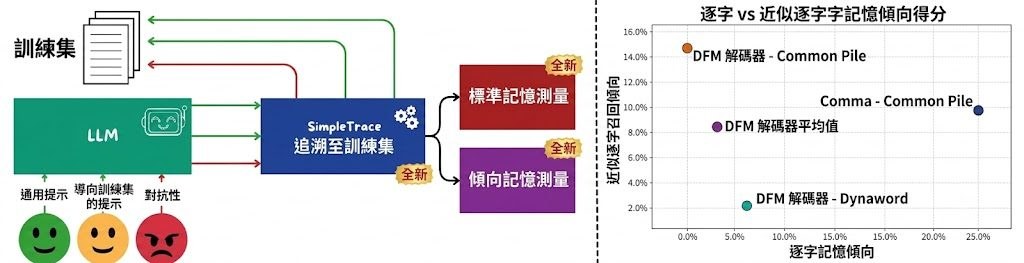
整個項目的運作有兩大部分。PropMe 負責定義指標與分析邏輯;SimpleTrace 是一個建基於 infini-gram 的輕量離線追蹤流水線,負責為訓練語料建立索引、把模型生成結果對應回來源文檔,再計算出 verbatim、near-verbatim 與傾向轉換後的記憶性指標。流程包含索引建立、unigram 機率預計算、生成結果追蹤、驗證與傾向指標運算等步驟,資料夾 README 都各有詳細說明。
PropMe 以兩個完全開源的模型——Comma 與 DFM Decoder——在 Common Pile 與 Dynaword 兩份雙語資料集上做實驗。結果顯示能力(capability)與傾向(propensity)之間存在穩定落差:前綴攻擊能引出明顯的記憶痕跡,但日常或資料集特定的提示下,傾向分數普遍偏低。另一個有趣的發現是,從 Comma 持續預訓練而成的 DFM Decoder,對 Common Pile 的記憶能力與傾向都下降,顯示後續訓練若側重不同資料,能降低既有的記憶行為。
這個項目適合關注模型安全、版權與資料外洩的研發人員、模型審計人員及學術研究者。如果你正在評估自家模型的記憶風險,PropMe 提供了把「最壞情況抽取性」與「日常洩漏傾向」分開呈現的具體做法,比單純跑前綴攻擊更能反映真實部署風險。
重點摘要:
- 問題意識:區分模型「被逼才會背」與「日常會背」兩種不同行為。
- 核心框架:PropMe 負責傾向指標,SimpleTrace 負責把生成結果追蹤回訓練文檔。
- 技術基礎:建立在 infini-gram 之上,支援 verbatim、near-verbatim 與傾向轉換指標。
- 評估模型:Comma 與 DFM Decoder,資料集涵蓋 Common Pile 與 Dynaword 兩種語料。
- 實用價值:為模型記憶性審計提供比純粹對抗攻擊更貼近真實使用的衡量方式。