過去兩年,影片生成模型(Video Generation Models)的能力突飛猛進,但大多數評估都停留在「畫面是否好看」這個層面。來自新加坡國立大學 Show Lab、牛津大學及 Tencent 的研究團隊推出 Dream.exe 項目,提出一個更根本的問題:模型在影片中「夢到」的操作動作,機械人真的能照著做嗎?
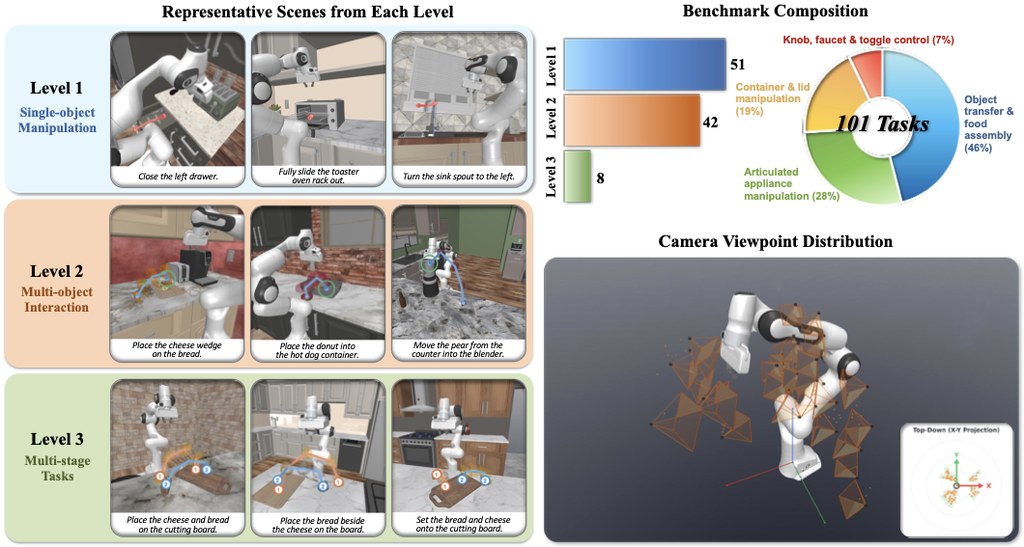
Dream.exe 的運作流程相當直觀。系統接收一張場景圖片與任務描述後,會先生成一段操作影片,再把當中的動作提升為 3D 機械人軌跡,最後放到物理模擬器中執行。研究團隊採用了 101 項任務,這些任務從 RoboCasa 數據集中精心挑選,並按物理複雜度分為三個等級,評分維度涵蓋視覺品質、軌跡擬真度,以及最關鍵的執行成功率。
評估涵蓋 8 款模型,包括前沿閉源模型如 Veo 2 及 Sora、開源模型如 Wan2.1,以及專為機械人設計的影片生成器。所有模型都採用統一的評測協議,確保比較公平。
這份研究帶來幾個值得留意的地方:
- 物理知識其實已經藏在生成模型之中。 部分模型在沒有經過任何機械人專項訓練的情況下,仍能達到可量度的執行成功率。
- 影片好看不代表能執行。 物理合理性評分與任務成功率的相關性極低,意味著以視覺質素判斷模型是否「有用」並不可靠。
- 長時任務仍是痛點。 需要多階段協調的操作,會迅速暴露現有模型的極限。
對於機器學習研究者、機器人工程師,以及關注世界模型(World Models)與具身智能(Embodied AI)發展的讀者,這份基準測試提供了一個可重複使用的評估框架。研究團隊已表示將開源代碼、基準數據及評測工具,預計會引起不少關注。整體而言,Dream.exe 把影片生成模型從「看的技術」推向「用的技術」,是 2026 年具身智能研究中具代表性的方向之一。