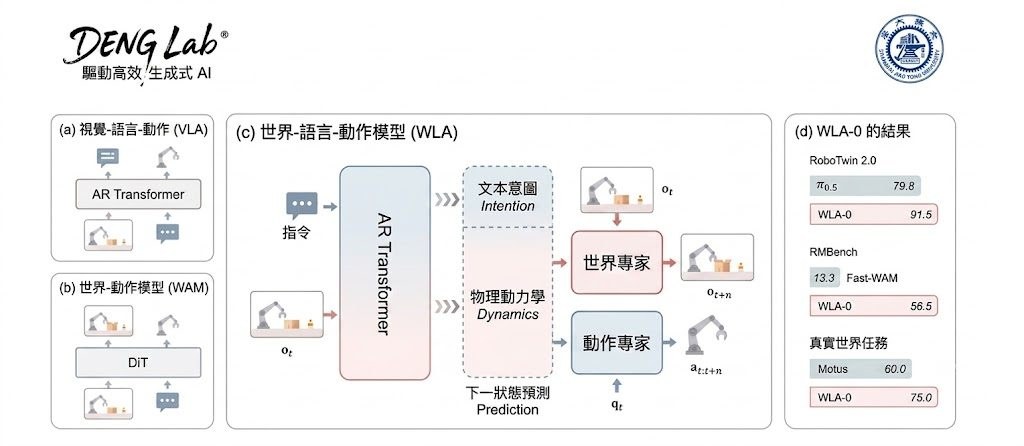
WLA(World-Language-Action Model)由上海交通大學 DENG 實驗室推出,定位為一個統一世界建模、語言推理與動作合成的官方實現項目。簡單來說,研究團隊嘗試讓同一個 AI 系統同時處理「理解世界」、「理解語言」以及「產生動作」三種任務,而不再需要三個獨立模型分工合作。這對於機器人、遊戲 AI 以及需要即時決策的互動系統來說,是一條值得關注的技術路徑。
目前這個項目仍處於預告階段,程式碼與模型權重計劃在 6 月 18 日之前開源釋出,官方提供了展示影片展示其運作效果。在動手實作方面,潛在使用者短期內只能先關注儲存庫的更新,等待權重釋出後再評估本地部署或 API 整合的可能性,項目本身亦未透露具體支援的模型清單。
這個項目的創新方向,是把感知層、認知層與執行層的概念放在同一個訓練框架下學習,減少傳統流水線中模組之間的介面損耗。對於機器人研究團隊、強化學習開發者,以及探索通用代理人(General-purpose Agent)架構的工程師而言,WLA 提供了一個可參考的新設計樣板。效能數據與基準測試結果,則有待官方釋出後再做比較。
以下整理幾個重點供參考:
- 統一框架:把世界模型、語言模型與動作模型合而為一,降低多模態系統的整合成本。
- 學術背景:來自上海交大 DENG 實驗室,屬於官方實作項目。
- 適用場景:機器人控制、互動式代理人、強化學習等需要即時決策的應用。
- 目前狀態:程式碼與權重即將於 6 月中前公開,尚未有完整基準評估。
- 使用建議:在權重釋出前,讀者可先研究展示影片與後續論文,掌握其訓練思路再決定是否整合。
若你正在尋找一個把感知與行動串起來的新框架,WLA 值得加入觀察清單。