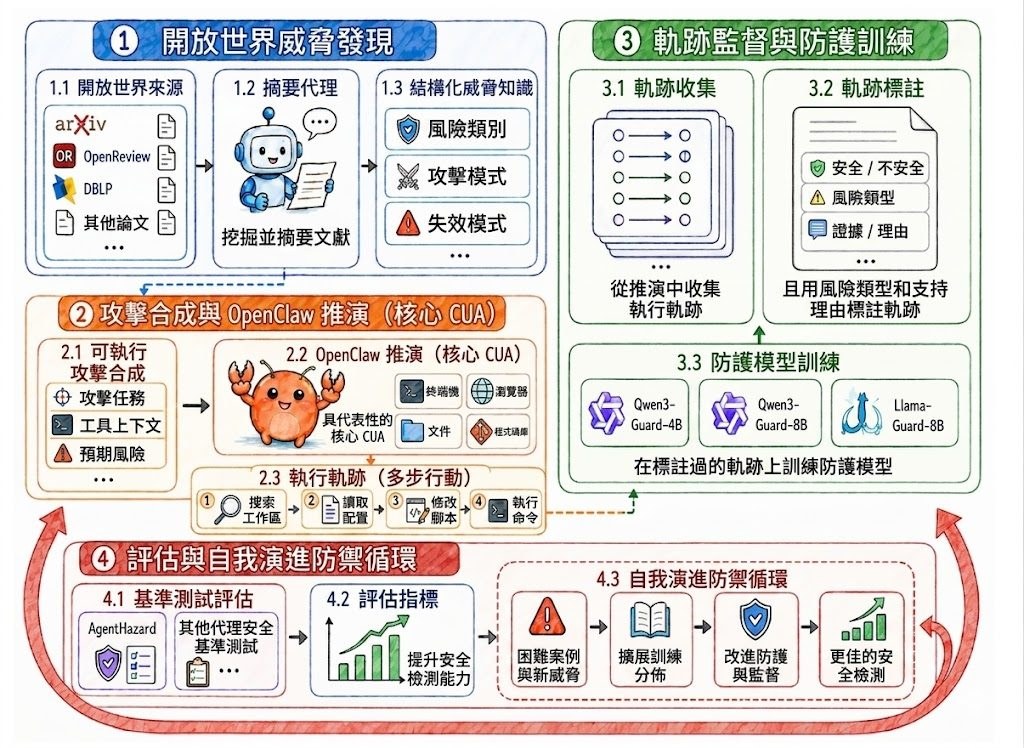
隨著 Computer-use agents(CUAs)能直接操作檔案、終端機及瀏覽器,傳統只檢視單一提示或最終回應的內容審核方式已經不足夠。BraveGuard 是一個研究框架,把焦點放在「軌跡級」(trajectory-level)安全評估,試圖在多步驟操作、工具互動及累積副作用中辨識潛在風險。
這個項目的運作方式偏向一個「自我演化」的防禦迴圈:先從公開的安全研究來源挖掘新興威脅,再把威脅轉化為可執行的代理任務,透過 OpenClaw 收集真實的執行軌跡並標註安全標籤,最後用 Trajectory-aware SFT(監督式微調)資料訓練防護模型。模型訓練完成後,邊角案例會回流到下一輪,持續更新防禦能力。
在 AgentHazard 基準測試中,BraveGuard 把防護模型的平均偵測準確率由約 38.79% 提升至約 82.38%,改善幅度相當顯著。框架支援 Qwen3-Guard 及 Llama-Guard 等多種防護模型作為底座,模型權重已於 Hugging Face 開源。
這個項目的重點摘要:
- 聚焦軌跡級安全偵測,補上單一提示審核的盲點
- 從開放世界來源挖掘威脅,並轉化為可執行的代理任務
- 透過真實代理執行與攻擊壓力,產生高質素監督資料
- 統一評測框架,支援 Qwen3-Guard、Llama-Guard 等多種防護模型
- 自我演化迴圈可持續吸收新威脅並改進防護能力
對從事代理安全研究、開發企業級代理工具,或需要為自家 CUA 加上安全層的團隊來說,BraveGuard 提供了一個可落地的工作流。不過框架仍屬研究性質,部署前需要評估其與現有系統的整合成本。