過往要讓AI理解3D場景,往往需要設計專屬的模型架構、複雜的損失函數,還要加上各種資料增強手段。Meta與Princeton合作提出的VLM³(Vision Language Models Are Native 3D Learners)卻反其道而行,主張標準VLM天生就是3D學習者。
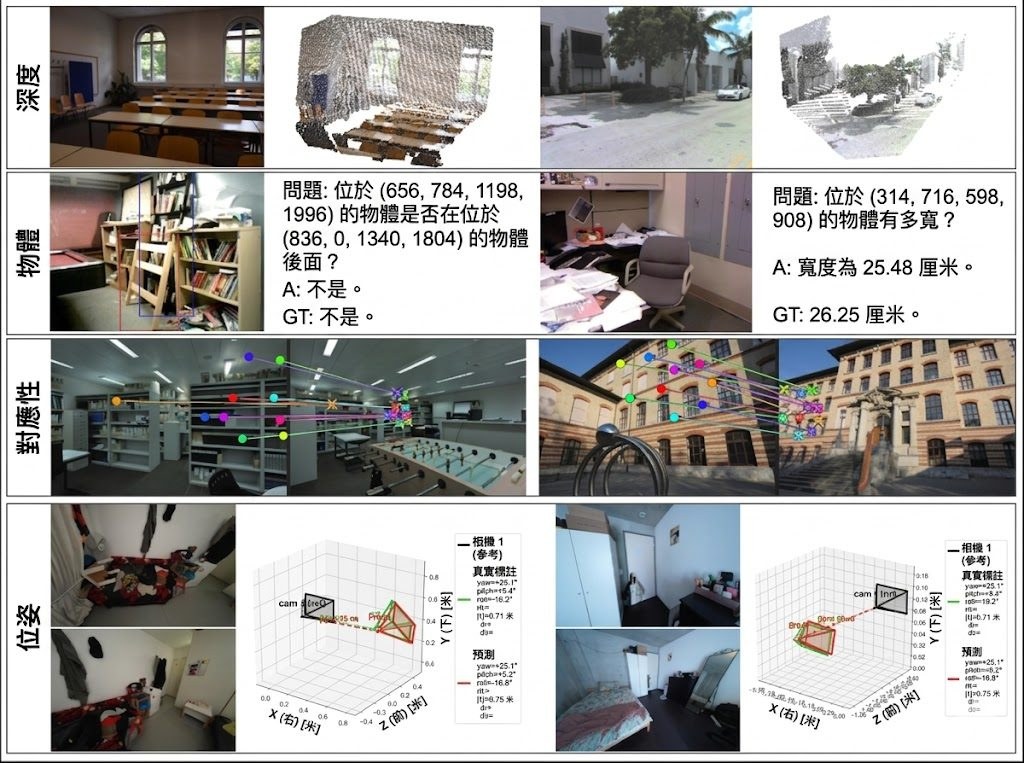
有效的 3D 學習主要靠三點 —— 焦距統一(focal length unification)、文字式像素參照(text‑based pixel reference)、以及資料混合與擴展,而不是新架構、大模型、heavy augmentation 或複雜 regression loss。
VLM³會先把輸入影像縮放至相同焦距(以1000像素為例),解決相機內參歧義;需要指涉物件或像素時,就以文字配合標準化座標範圍(例如[0, 2000)或[0, 1000))來表達,整個過程不需更動架構或加額外編碼器,僅用標準的文本監督微調(SFT)訓練。
在效能上,VLM³於多個3D基準上繳出亮眼成績:在物件級3D理解上超越SpatialRGPT;於度量深度估計上比肩UnidepthV2與Moge-2,把DepthLM的準確度由0.84提升至0.9;在像素對應上勝過DKM與RoMa;相機姿態估計方面則與DepthAnything3持平並超越VGGT。
這套方法適合關注3D視覺的開發者與研究團隊,特別是希望以單一通用模型涵蓋深度、對應、姿態與物件理解等任務的人。對於想從規模化資料入手,而非投入大量工程設計特定模型的場景,VLM³提供了一條相當務實的路徑。模型目前尚未公開,讀者可先留意論文及官方項目頁面的後續更新。
重點摘要:
- 焦距統一:把輸入影像縮放至同一焦距,免去相機內參歧義。
- 文本式像素參考:以標準化座標文字指涉像素,不需加標記或新架構。
- 資料規模化勝過複雜設計:證明擴展資料與標準SFT已足夠,不需任務專屬模型。
- 多項指標比肩專家模型:深度、像素對應、相機姿態等任務達到頂尖水準。
- 統一輸出域:以文字作為統一介面,讓通用模型同時處理多樣3D任務。