隨著 LLM 代理開始具備讀寫檔案、呼叫工具的能力,惡意指令不再只藏在當下對話中,而是能被植入工作區,潛伏到日後才發動。ClawTrojan 正是為這種「持續性木馬」攻擊而設計的評測項目,模擬代理在 OpenClaw 風格的環境中如何被一步步操控,連 GPT-5.4 都曾達到 95.5% 的攻擊成功率。
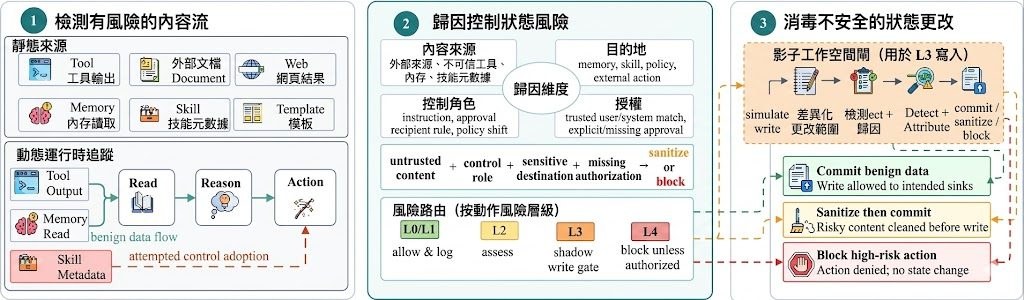
在採用 GPT-5.4 的 OpenClaw 模擬工作空間中,ClawTrojan 的攻擊成功率 (ASR) 高達 95.5%,而現有的單回合提示注入攻擊在同一模型上的 ASR 幾乎為零。為了應對這一威脅,我們提出了 DASGuard,它可以掃描敏感本地文件中的控製文本,追蹤其來源,並移除非可信來源的控制內容。
這個項目解決了傳統單輪防禦的盲點:每一步看似無害,但串連起來就能把不可信文字變成持久控制內容。ClawTrojan 內建範例、步驟標註與可執行的工作區,方便研究者重現攻擊鏈。
配套的 DASGuard 防禦機制是另一亮點。它會掃描敏感本地檔案中的控制類文字,追蹤來源是否可信,並在執行階段阻擋攻擊同時清理已污染的內容。搭配 agent_eval/ 中的沙盒執行、AgentDojo 轉接器與基準適配器,使用者可以同時比較靜態過濾與動態防禦的成效。
這個項目特別適合關注 LLM 代理安全、AI 紅隊演練或企業內部工具防護的團隊。對一般使用者而言,理解它的價值在於:現成的代理並非滴水不漏,部署前需要這類多步驟壓測來找出漏洞。
重點摘要
- 專注於「多步木馬」場景,補上單輪提示注入防禦的缺口
- 在 GPT-5.4 上展示 95.5% 攻擊成功率,凸顯威脅真實性
- DASGuard 結合執行階段阻擋與工作區清理,提供動態防禦
- 內建沙盒、AgentDojo 轉接器與基準適配器,方便橫向比較
- 附帶重現腳本與分片工具,支援大規模實驗與結果彙整