EarlyTom 是一個針對 Video Large Language Models(Video-LLMs)而設的 token 壓縮項目,目標很清晰:在不重新訓練模型的前提下,減少影片理解時要處理的視覺 token 數量。它主要處理推理速度慢、計算量高這個痛點,尤其是影片內容比圖片更長、更重,模型很容易在前段編碼就耗掉大量時間。
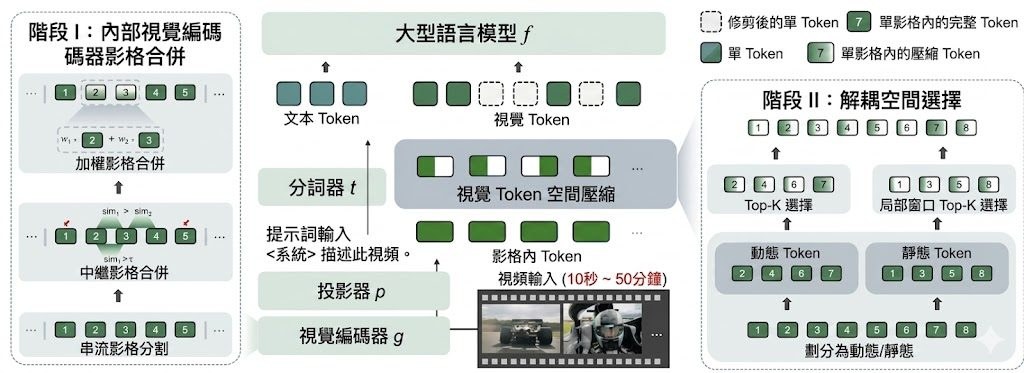
這個項目的核心想法,不是等資料全部進入模型後才壓縮,而是更早在 vision encoder 階段動手。EarlyTom 會利用早期 transformer layers 的 attention 訊號,先找出冗餘 token,再做裁剪;另有可選的 inner compression,會在 LLM backbone 指定層以 DPC-KNN 做 token 合併。這種早期壓縮方式,重點在於連 vision encoder 的負擔都一併減少。
使用上,項目是建基於 LLaVA-NeXT,並可包裝 LLaVA-OneVision 模型;程式層面是把已載入的模型再套用 EarlyTom。對已經在跑影片問答、影片描述或多模態理解流程的人來說,這代表可在原有模型管線上加入壓縮機制,而不一定要改動整個訓練流程。
- 免訓練(training-free)壓縮,部署門檻相對較低
- 分為 outer compression 與 optional 的 inner compression
- 重點改善 Time-to-First-Token(TTFT)、throughput 與 FLOPs
- 依賴早期 attention 訊號挑走冗餘視覺 token
- 相關模型與框架包括 LLaVA-NeXT、LLaVA-OneVision、Qwen2
從公開資料看,作者以 lmms-eval 進行評測,並在論文內容提到會比較 MVBench、EgoSchema、LongVideoBench 與 VideoMME 等常見影片理解基準。結果描述顯示,它在維持接近 full-token 方法準確度的同時,TTFT 最多可降至 2.65×,亦有更高 throughput;不過不同模型大小、影片長度與硬件配置下,實際增益仍要分開看。
這個項目較適合已經使用 Video-LLMs 的研究者、工程團隊,或想在資源有限環境中提升影片理解效率的人。若你關心的是模型答得準之餘,也要更快開始輸出結果,EarlyTom 的價值就在於它把壓縮時機提早,直接針對最花時間的部分下手。