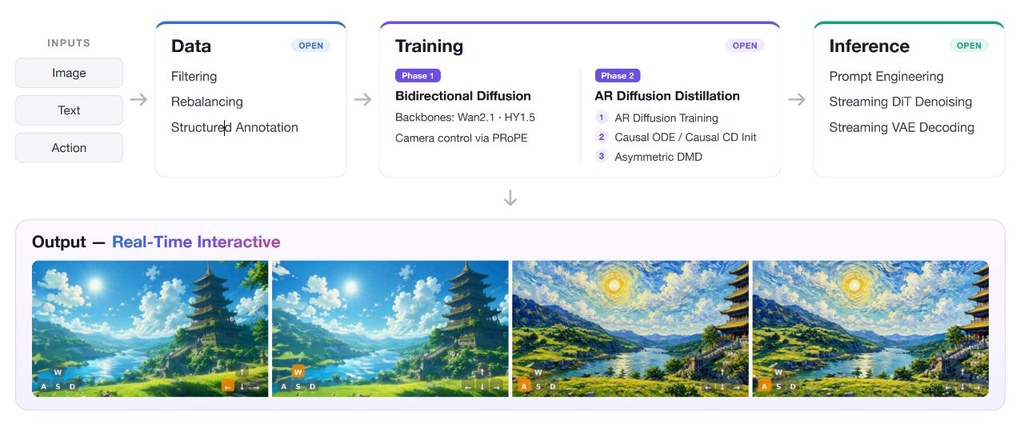
minWM 的定位很清楚:它不是再提供一個新模型,而是把建立 video world model 的整條流程拆開,讓人由 bidirectional T2V(Text-to-Video)或 TI2V(Text-and-Image-to-Video)基礎模型,一步步轉成 action-conditioned video world model。對剛接觸這個領域的人來說,這種完整路線比只放權重或單段程式碼更有幫助。
這項目重點不是「裝完即用」,而是按它提供的資料處理、訓練、蒸餾與推理流程逐段走。項目公開了 data → training → inference 的全流程,並提供 example data、runnable scripts、Claude Skills 與新手知識整理,方便你先跟一次標準流程,再按自己需要改 backbone、資料分佈或控制方式。
它要解決的問題,在於高質影片生成模型未必等同可互動的 world model。要做到低延遲、可因果 rollout、可回應鏡頭軌跡等操作,背後需要 camera control、autoregressive training、few-step distillation 及 streaming inference 等整套機制;minWM 正是把這些環節模組化,並用 Causal Forcing、Causal Forcing++、Teacher Forcing 與 asymmetric DMD 串連起來。
- 支援 4-step DMD inference,並提到 multi-GPU sequence parallelism
- 可用 pose strings 或 JSON 檔控制 camera trajectory
- 提供 debug-world-model,整理 loss NaN、jitter、camera drift 等常見失敗模式
- 提供 integrate-new-backbone,示範怎樣接入新的 video DiT
- 參考 backbone 包括 Wan2.1-T2V-1.3B、HY1.5-TI2V-8B,亦提到 HY Action2V、HY TI2V、Wan Action2V
項目的新意在於它同時處理「怎樣訓練」與「怎樣改造」。除了支援不同 backbone 與 condition injection 方式,也把團隊累積的排錯經驗與 Claude 協作流程寫進項目,令研究者或工程人員不只看到結果,還能理解常見錯誤從哪裡出現。
它的目標是 real-time interactive video world models,並附有對 camera trajectory quality、controllability training steps、minimal batch-size requirements 的實驗分析。不過公開資訊較偏向框架與流程,若你想比較單一模型跑分,這個項目更適合當作建立、重現及擴展 World Model 的工作底座。