LiteCoder 是一個圍繞終端機代理訓練的項目,核心目標很清楚:讓小型和中型 code agent 模型,在 command-line 工作流中做得更好。它今次公開的不只是 LiteCoder-Terminal-SFT 模型與資料,還包括 11,255 條軌跡資料,以及 602 個附完整測試的 Harbor terminal environments,整體比單放模型更有研究價值。
一般 coding model 比較像「幫你寫 code」。
這個更像「幫你在 terminal 裡完成任務」,所以它的重點是行動能力,不是只會生成代碼片段 。
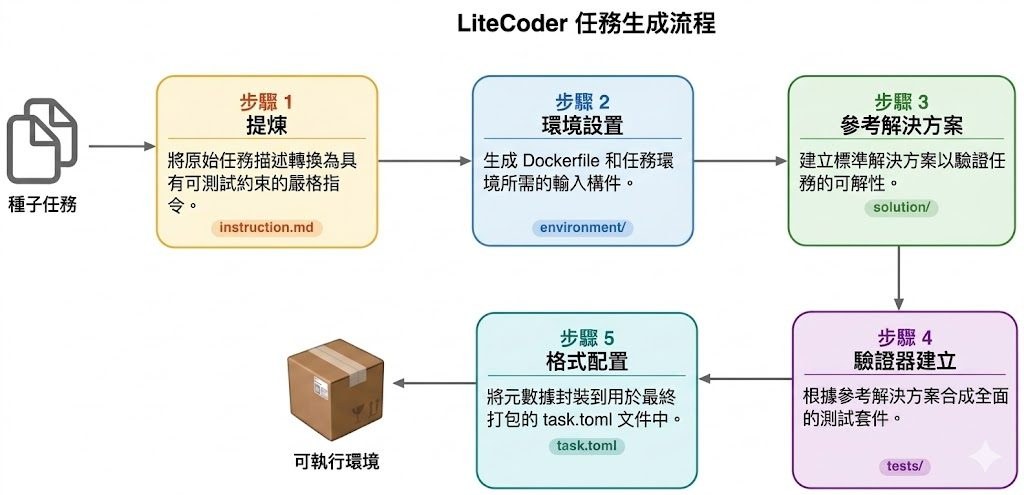
這個項目主要回應兩個常見難題:一是 terminal agent 訓練資料難找,二是很多任務描述無法直接驗證成效。LiteCoder 以可執行環境取代純文字題目,並把任務整理成可測試約束,令模型學到的不只是答題格式,而是多步驟操作、回饋修正與狀態轉換。
使用時可先從已公開的模型與 datasets 入手,再配合 GitHub 內的 code 檢視資料結構、環境生成方法與訓練脈絡。對研究者或工程團隊來說,這種「模型+資料+環境」一套齊的形式,方便重現結果,也方便延伸到 RL、偏好優化或自家 terminal 任務。
- 已公開相關模型:LiteCoder-Terminal-30b-a3b-sft、LiteCoder-Terminal-4b-sft
- 已公開相關資料:LiteCoder-Terminal-SFT、LiteCoder-Terminal-World-Model-SFT、LiteCoder-Terminal-RL-preview
- 資料規模由不足 1k 擴大到 11,255 trajectories,涵蓋 10 個 domains
- 訓練由 Terminus-only 擴展到 multi-scaffold,任務類別也加入 coding、scientific/numerical computing、games
- 基準結果較前一版提升,並報告 Terminal Bench 1.0/2.0/Pro 與 pass@4
從論文附帶資訊看,Qwen-family models 經過 Supervised Fine-Tuning(SFT)後,表現明顯優於 base model;其中 32B 版本在 Terminal Bench 1.0、2.0、Pro 的 pass@1 分別達 29.06%、18.54%、34.00%。數字不算誇張,但對長步驟 terminal 任務來說已有參考意義。
這個項目特別適合想研究 Computer-use agents、CLI agent、合成環境生成,或想建立可驗證訓練流程的人。若你關心的不是聊天回覆,而是模型能否在終端機內逐步完成工作,LiteCoder 提供了一條相對完整而且可追蹤的路線。