ProRL 不是一般只估你下一次會按甚麼的推薦模型,而是先安排幾個中間項目,慢慢把興趣帶向目標項目。對影片平台或電商來說,這比直接硬推陌生內容更有策略。
項目把 semantic-ID 表示和強化學習結合,先用短碼描述項目,再學一條推薦路徑。評分不只看點擊,還同時看目標興趣提升、目標排名提升,以及中間項目的點擊率。
- 多目標設計:把 IoI、IoR、CTR 一起納入,方向較完整。
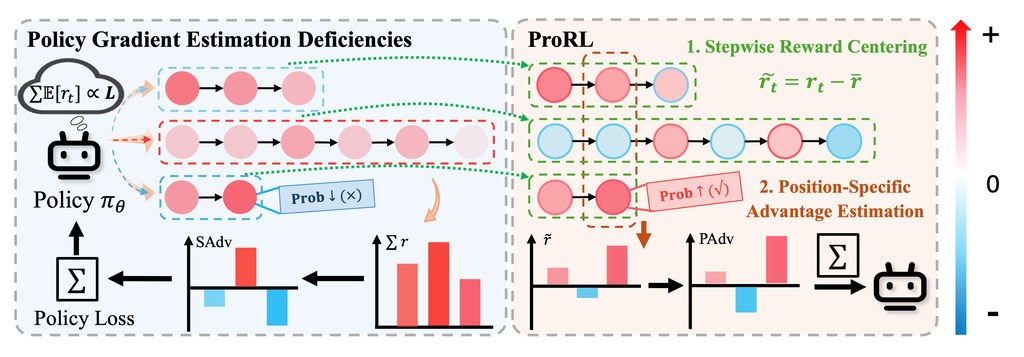
- 方法亮點:加入 Stepwise Reward Centering 與 Position-Specific Advantage Estimation,重點是修正長路徑偏差並減少訓練噪音。
- 訓練穩定性:配合預訓練參考策略和 KL 正則,令訓練更穩定。
- 工程層面:支援 Accelerate 多 GPU,較適合研究環境。
這個倉庫已分成預訓練和強化學習兩段,亦提供可直接跑的 scripts,checkpoint 與日誌會自動保存。使用時最好已有 Python 3.11、CUDA 12.4 和多 GPU 條件,否則較難完整重現。
論文摘要指出,它在三個真實數據集上勝過現有主動推薦方法。整體來看,這個項目較適合做推薦研究、序列決策實驗,或想了解 ProRL、預訓練參考策略與 semantic-ID 如何配合的人。