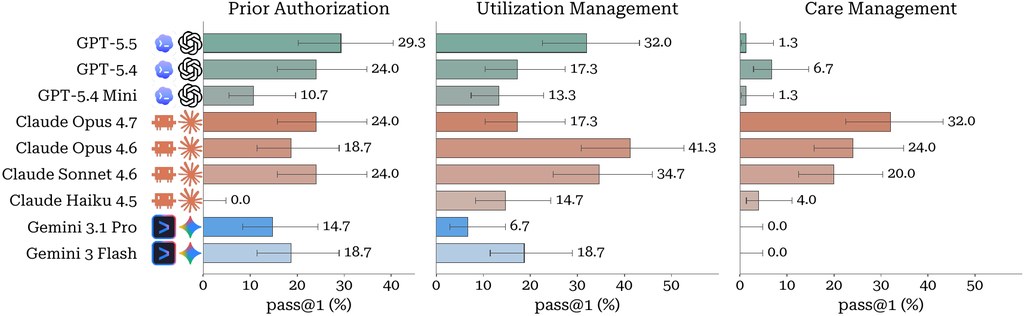
chi-bench 係一個用來評估 AI 代理嘅基準環境,重點唔係問答,而係要模型喺模擬出嚟嘅美國醫療工作流程中,逐步完成整個個案。它覆蓋事前授權、保險方利用管理,以及群體照護管理三類長流程工作,目的是測試 AI 有冇能力處理多步驟、規則密集、而且涉及多角色協作嘅任務。
官方摘要提到它使用 20 個 healthcare apps、87 個 MCP tools,以及一份 1,290+ 文件的 managed-care operations handbook 作為任務依據。
實際使用時,研究者通常會先準備對應嘅 API 金鑰,再揀選代理框架同模型跑任務,之後由內建評審機制按每次結果評分。每個任務會提供臨床個案、模擬工作系統,以及大量操作手冊,AI 要透過工具呼叫同撰寫文件去推進流程,唔係單靠生成一段答案就算完成。
它最有意思嘅地方,在於把醫療行政流程入面最麻煩嘅部分具體化:規則多、文件多、系統多,而且中途可能要反覆互動。相比一般 benchmark 只量度單步推理,chi-bench 更接近現實世界,因為它會考驗模型點樣跨應用程式、跟住政策辦事,並保持長時間決策一致。
- 涵蓋 3 大醫療流程場景,屬於端到端任務評估
- 以約 20 個模擬醫療應用及大量文件作為操作環境
- 支援多類代理與模型比較,包括 Claude、OpenAI、Gemini 及開源權重路線
- 排行榜以 pass@1 為主,亦可保留多次試跑作額外分析
從現有資料睇,呢個基準對現時最強模型都相當困難,代表它有一定鑑別力,唔會輕易被高分掩蓋弱點。已知相關配置包括 Claude Code 配 Claude Opus、OpenAI/Codex 路線、Gemini CLI,以及經 OpenRouter 接入嘅 Hermes、OpenClaw、DeepAgents 等;至於具體表現會隨代理包裝方式同工具使用能力而有明顯差異。
對 AI 代理研究員、醫療流程自動化團隊,甚至想了解「模型識唔識真做事」嘅產品人員嚟講,chi-bench 都幾有參考價值。不過它聚焦美國醫療制度同受規管流程,閱讀結果時要留意場景限制,唔適宜直接當成所有行業嘅通用結論。