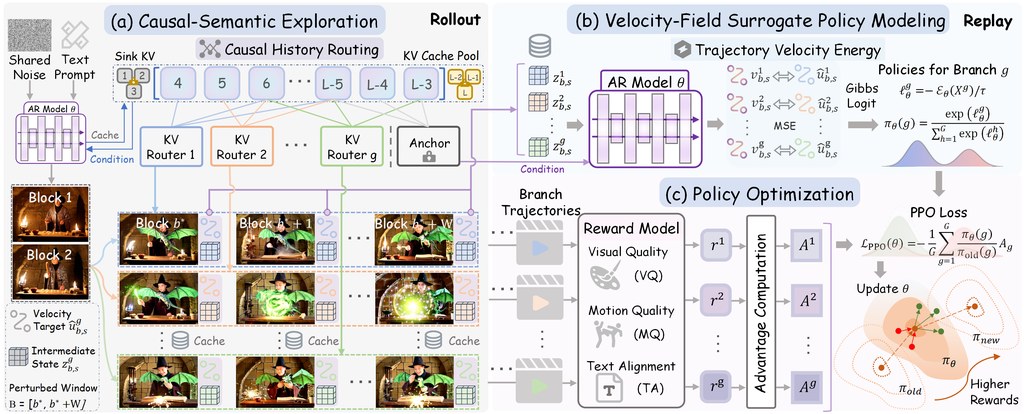
KVPO 係一個針對影片生成訓練流程嘅研究型專案,焦點唔係單純「生成到片」,而係令模型喺逐格、逐段生成嘅過程中,更穩定咁貼近文字提示同預期內容。對一般讀者嚟講,可以理解成:佢想改善 AI 影片成日出現嘅「開頭啱、之後走樣」問題。
呢個方法特別之處,在於佢唔只睇最後條影片好唔好,而係會喺生成途中做多條候選路線探索,再用獎勵模型判斷邊條路線更值得學。README 提到佢結合咗類似 PPO 嘅強化學習更新,以及對生成軌跡嘅機率估計,目標係令自動回歸影片模型學得更準。
實際了解同試用呢個專案,會由查看論文、專案頁面同釋出權重開始,再按設定準備對應環境、模型權重同資料。由於文件列出咗 H200、CUDA 12.8、Wan2.1 backbone,以及 HPSv3、VideoReward 等元件,較適合已有 GPU 資源、熟悉深度學習訓練流程嘅讀者,而唔係即開即用型工具。
- 主要處理影片生成中內容偏離提示、時間一致性變差等問題
- 核心做法係先探索多個生成分支,再用獎勵分數引導學習
- 研究重點放喺自動回歸影片模型,而唔係一般圖片生成
- 文件顯示會配合 Wan2.1-T2V-1.3B 等 backbone 使用
- 仲會涉及 HPSv3、VideoReward 呢類評分或獎勵相關模型
整體而言,KVPO 比較適合關注影片生成訓練方法嘅研究者、工程師,或者想比較唔同對齊策略嘅團隊。對非技術用家,佢未必係直接拎嚟出片嘅方案;但作為觀察新一代影片模型點樣「學識跟指令」嘅方向,呢個專案幾有參考價值。