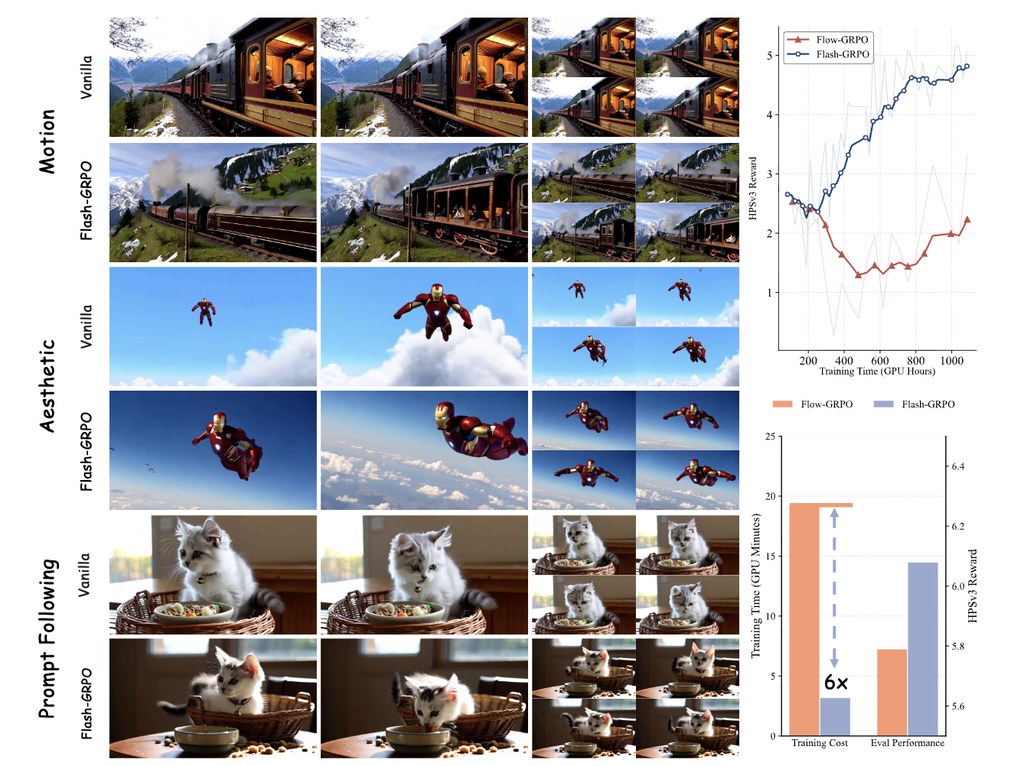
Flash-GRPO 針對的是影片生成模型訓練中一個很實際的難題:要令模型更貼近人類偏好或評分標準,傳統做法往往要走完整訓練軌跡,計算量高、時間長,對硬件要求亦相當重。這個專案提出單步式優化框架,重點是用較低運算預算,換取更有效率的對齊效果。
從公開資料來看,它主要面向影片擴散模型,並配合獎勵模型一同使用。實際動手時,需要先準備基礎模型 Wan2.1-1.3B,以及 README 提到的 HPSv3 獎勵模型,再按專案提供的訓練流程啟動;現階段較適合已熟悉 Python、分散式訓練和 GPU 環境的人直接試跑。
這個方法較有意思的地方,在於它不只是「少做步驟」,而是嘗試處理時間步之間訓練訊號不穩定的問題。README 提到兩個核心設計:一個是維持同一提示詞在時間上的一致性分組,另一個是修正不同時間步梯度尺度不一致的情況,目標是令訓練更穩定,也更容易比較模型表現。
- 主打影片擴散模型的對齊訓練,而非一般文字模型微調
- 強調單步式策略優化,方向上比完整軌跡訓練更省資源
- 已在 1.3B 到 14B 規模模型做實驗驗證
- 相關基礎組件,包括 Wan2.1-1.3B 與 HPSv3
整體來說,Flash-GRPO 比較適合做生成式 AI 研究、影片模型訓練優化,或想評估低成本對齊方案的團隊。對一般用家而言,它不是即裝即用的成品;但對需要在有限 GPU 預算下提升訓練效率的人,這個專案展示了一條相當值得關注的技術路線。