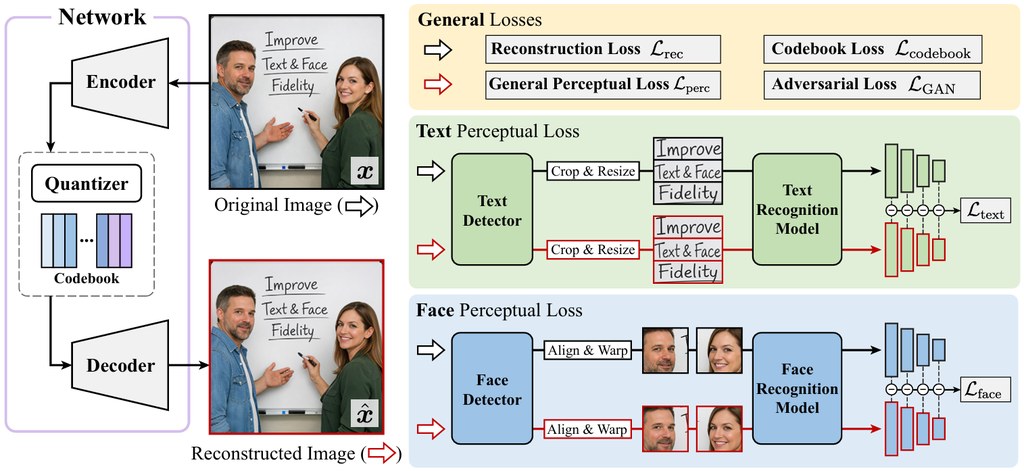
生成圖片時,最常令人出戲的往往不是背景,而是招牌上的字、海報上的字句,或者人臉五官的細節。InsightTok 針對的正正是這兩個難位:它不是直接改整個生圖模型,而是先改善圖片被「拆解成代碼」的方式,讓後續生成時更易保留重要內容。
實際使用上,這類專案較適合已經在做文字生成圖片、研究離散視覺 tokenization,或使用自回歸圖像生成流程的開發者與研究者。重點在於把原有流程中的視覺 tokenizer 換成 InsightTok 這一類方案,後面的生成模型理論上毋須大改,對現有管線算是較容易接入。
它的特別之處,在於沒有只用一般重建目標,而是更有意識地照顧局部而且重要的內容,例如文字區域與人臉區域。根據儲存庫提供的說明,它在相同壓縮率下,能做到更好的文字與人臉重建,同時只用 16× downsampling 和 16,384 個條目的 codebook,額外訓練成本亦相對有限。
- 主要改善圖片中的文字可讀性與人臉細節還原
- 可兼容標準自回歸圖像生成流程,毋須連下游模型一併重寫
- 在相同壓縮條件下,重建效果主打更清晰、更忠於原圖
- 設計上延續 VQGAN 風格 tokenizer 思路,但加強重點區域 supervision
- 相關脈絡包括離散視覺 tokenizer、VQGAN 風格方法,以及文字生成圖片模型
整體來看,InsightTok 吸引之處不在花巧功能,而在於它抓到生圖最常被批評的痛點,再用相對務實的方法補強。對一般讀者來說,可以把它理解成一個「令 AI 更識得保住字同樣貌」的底層零件;對技術團隊而言,它較像是一個可直接提升畫面可用性的基礎組件。