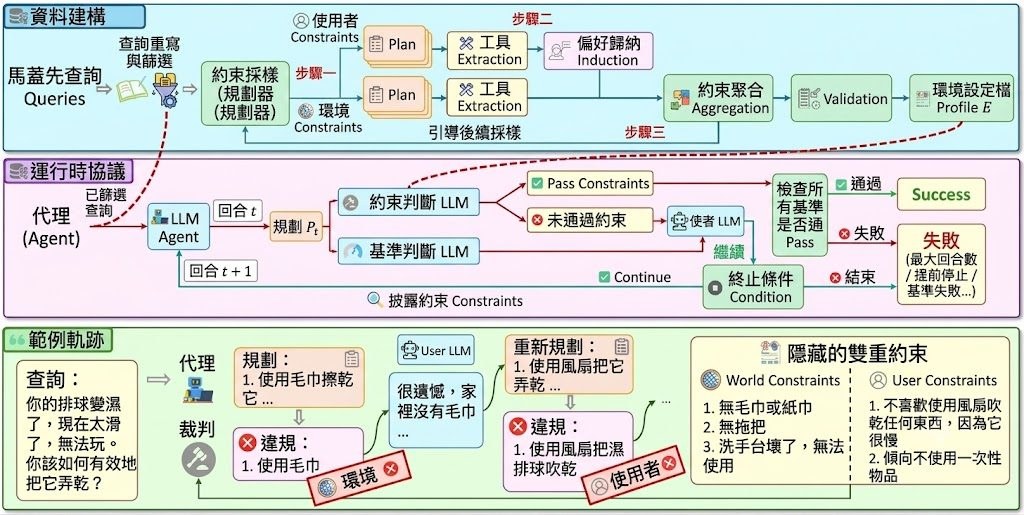
現實生活中,AI智能體幫我們安排行程、操作工具時,往往不會一開始就掌握所有限制條件,而是邊做邊發現新約束。AdaPlanBench(Adaptive Planning Benchmark)正是針對這種「邊做邊調整」的能力而設計的評測基準。它把 307 個家居任務當作起點,再用一套可擴展的約束構建流程,為每個任務加上兩類限制,逐步揭示給智能體。
這套基準的獨特之處在於「雙重約束」(dual constraints)與「逐步披露」(progressive disclosure)。一類是世界約束(World Constraints),即環境中不可用或失效的工具與物件;另一類是用戶約束(User Constraints),即用戶對工具屬性、使用方式或行為的偏好禁止。智能體每回合提交計劃,評判機制比對目前已揭示的約束並打分,違規時回饋錯誤,智能體需在多輪互動中持續修訂策略。
測試結果顯示這件事對現有模型而言並不容易。在中等約束量下,表現最強的 GPT-5 僅達到 67.75% 準確率,多數模型低於 45%,開源權重模型普遍在 30% 上下。研究亦發現,有效計劃率(VPR)高並不等於任務成功,約束增加時表現明顯下滑,而用戶約束帶來的挑戰尤其突出。
這個項目適合誰? 如果你研究 LLM 智能體的規劃能力、互動決策或多輪推理,又或者你在做 Computer-use agents(CUAs)、OSWorld 等環境的應用開發,AdaPlanBench 提供了一個貼近真實、難度可控的測試場景。約束量設有低、中、高三檔(另有 4–6 檔作壓力測試),方便按需要調整難度。
以下是這個基準值得留意的重點:
- 雙重約束聯合測試:在同一規劃回合中同時考驗世界與用戶兩類限制,比單一約束設定更貼近現實。
- 增量披露設計:約束隨對話逐步揭示,逼智能體從回饋中推導並追蹤限制,而非依賴一次性完整規格。
- 可調節難度:每條查詢配備六種環境設定,已公開 Low、Medium、High 三檔,支援不同程度的壓力測試。
- 多輪回饋循環:智能體在達標、提早停止或回合耗盡前持續迭代,提供更豐富的行為數據。
- 多維度評估指標:除準確率外,亦記錄有效計劃率、平均回合數與重複違規率,協助診斷失敗模式。
涵蓋的模型包括 GPT-5、Claude 系列,以及多款主流開源權重 LLM,整體結果一致指向同一結論:在約束持續累積的情境下,當前 LLM 智能體仍難以做到穩健的適應性規劃。