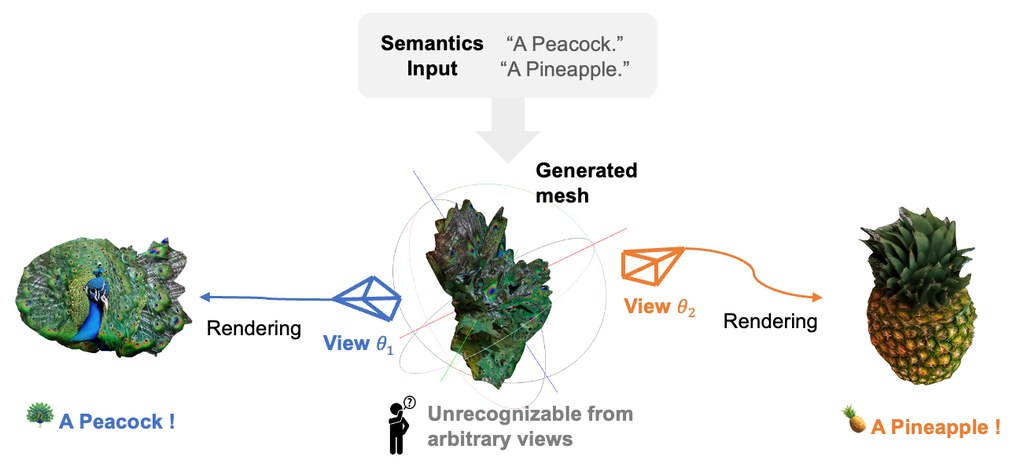
現有 3D visual illusions 做法,多數不是走 optimization-based methods,就是把兩個形體直接拼接。前者慢,還容易出現過飽和顏色;後者雖然直接,但會留下明顯幾何接縫,亦會有 semantic leakage。JanusMesh 提出的不是新訓練模型,而是一條 training-free pipeline,目標是把兩個文字提示融合成一個 3D mesh,並在指定視角各自呈現不同語意。
它的核心分成兩步:先用 cross-space dual-branch denoising,在 voxel 與 Signed Distance Field (SDF) 之間處理形體融合,再配合 CLIP 做 orientation alignment;之後再用 view-conditioned 2D diffusion 補貼圖與外觀。這種拆法的重點,不是單純把兩個物件疊上去,而是先解決幾何是否連貫,再處理不同視角看到的表面語意。
部署上,現有資訊顯示它較適合有 CUDA 環境的研究或圖像團隊,因為要安裝多個 CUDA extensions,例如 flash-attn、nvdiffrast、diff-gaussian-rasterization、pytorch3d。測試思路相當清晰:可先用 case 1 或 case 2 直接生成固定 voxel split 結果,再用 case 3 加入 CLIP pose search,比較視角對齊是否更穩定;另外也可調整 noise guidance、space control、t0 idx value 與 guided structure weight,觀察語意強度與形體穩定度之間的取捨。
JanusMesh 的表現頗有競爭力:生成時間約 3–5 分鐘,主打 geometric integrity、semantic recognizability、efficiency 都比同類方法好。不過它目前更像研究型工具,適合做 3D 內容展示、視覺實驗、生成式藝術或學術比較;若想要任意角度都自然,文中亦明言這類物件在非目標視角本來就可能難以辨認,這其實是 3D 視覺錯覺成立的一部分。
- 項目類型:一個 training-free 的 3D 生成流程,解決雙語意 3D visual illusions 的幾何接縫、語意外漏與生成速度問題。
- 最值得留意的差異:不是 per-shape optimization,也不是 direct concatenation,而是先做 cross-space 幾何融合,再做 view-conditioned 外觀細化。
- 較適合的情境:3D 生成研究、視覺傳達、展覽內容、概念設計,以及想比較多種 3D illusion 範式的團隊。
- 性能重點:論文聲稱 3–5 分鐘可完成,較傳統 SDS-Based Methods 快,亦減少 oversaturation 與 seams。
- 相關模型/組件:CLIP、2D diffusion、voxel、Signed Distance Field (SDF)、flash-attn、nvdiffrast、diff-gaussian-rasterization、pytorch3d。