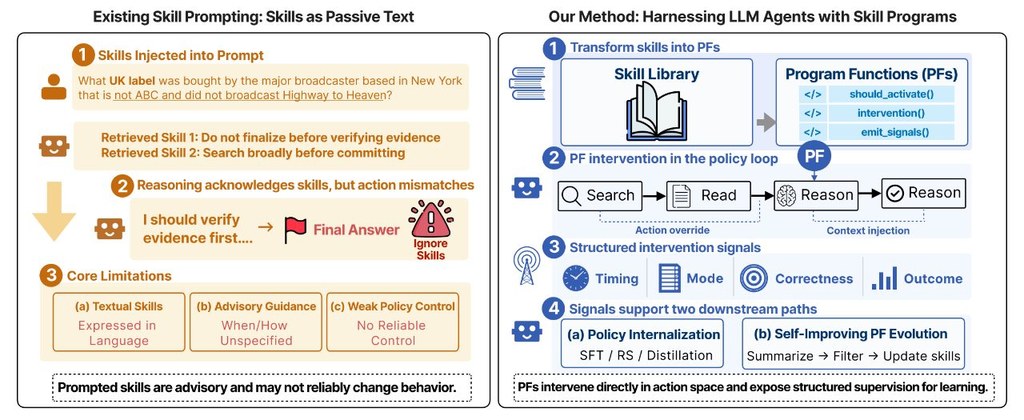
這篇論文介紹 HASP,一個用來提升大型語言模型代理表現的框架。它想解決的核心問題很直接:以往不少代理會把過往經驗當成文字提示,但這些提示很多時只是「建議」,未必會在出錯前真正介入。
HASP 的做法,是把技能轉成可執行的 Program Functions(PFs)。簡單理解,PFs 會在代理進行推理、搜尋或寫程式時,檢查當前狀態和下一步動作;如果偵測到常見失誤,例如太早下結論、重複無效步驟,便會插手修正,或者補充有用脈絡。
這個項目的特別之處,在於技能不再只是放進提示詞的文字,而是能夠明確決定「何時啟動」和「怎樣改動下一步」。論文亦指出,HASP 具模組化特性,可在推論階段直接介入代理循環,也可用於後續訓練,甚至讓系統逐步整理和演化已驗證的技能庫。
重點可概括為:
– 把經驗技能由被動提示變成可執行規則
– 可在失誤風險較高的節點主動介入
– 適用於網頁搜尋推理、數學推理與編碼任務
– 既可免訓練使用,也可配合後續訓練與自我改進
如果你正在做代理工作流、工具調用或長步驟推理,這個項目特別值得留意。論文報告顯示,在網頁搜尋推理中,單靠推論階段的 PFs,平均表現比多輪 ReAct Agent 提升 25%;結合後續訓練與受控演化後,對 Search-R1 的提升達 30.4%。
整體來看,HASP 的價值不只是「再加一些提示」,而是為代理加入可重用、可驗證、可介入的技能機制。文中未有把所有細節簡化成通用產品指南,但對想提升代理穩定性、減少重複犯錯的人來說,它提供了一條相當清晰的方向。