專案《When Vision Speaks for Sound》t提供官方程式碼,核心目標不是做一般影音問答,而是檢查支援影片的多模態模型,究竟有沒有真正理解聲音,還是只靠畫面和語意猜答案。它提供模型、評估介面和訓練流程,方便研究者重現實驗或改造自己的測試方式。
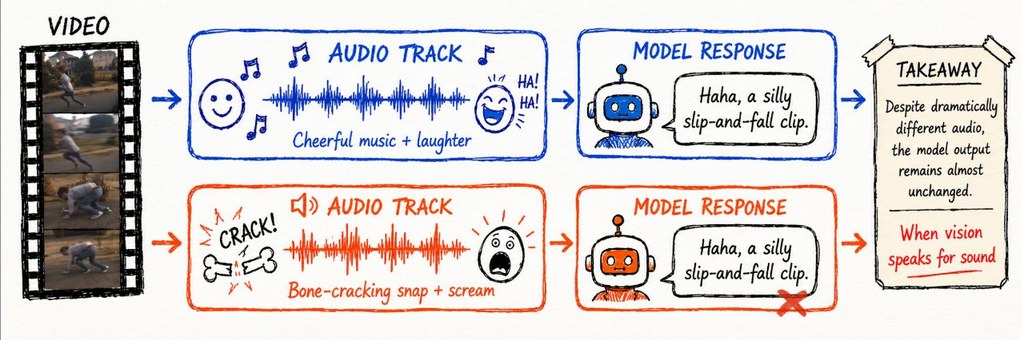
儘管支援視頻的多模態大語言模型(video-capable MLLMs)進步很快,但研究發現它們在視頻中表現出的「音頻理解」能力往往是由視覺驅動的:模型其實是依靠視覺線索來推斷、甚至幻想出聲音相關的資訊,而不是真正去檢查或分析音頻串流本身 。
這個問題普遍存在於:
最先進的開源全能模型(omni models)
主要閉源模型供應商(如 Google 和 OpenAI)的頂級模型
換句話說,這些模型看起來能「聽懂」視頻中的聲音,但實際上它們只是「看」畫面來猜聲音是什麼,並沒有真正處理音頻數據,因此容易產生錯誤或幻覺(hallucinate)。
先準備好影片和音訊資料,再把資料登記到 LLaMA-Factory 的資料設定中,之後就可以用它的 SFT 或 DPO 格式去訓練。專案也支援把樣本寫成 ShareGPT 風格,讓每條資料同時帶上 <video> 和 <audio>,方便模型學習在多模態情境下作答。
它比較特別的地方,在於採用介入式診斷框架 Thud,專門測試模型是否真的有做音訊驗證,而不是只走視覺捷徑。這種設計對研究「模型到底看了甚麼、聽了甚麼」特別有用,也比單純準確率更能揭示模型行為。
- 可用來評測影片語音、音畫同步、時間延遲等問題
- 適合做多模態模型研究、除錯和基準測試
- 支援 SFT 與 DPO 訓練流程
- 可接入 LLaMA-Factory 一起使用
- 相關模型與框架重點包括 Thud、LLaMA-Factory 以及多種可處理影片的多模態模型
整體來說,這個專案更像是一套「檢查工具」,而不是面向一般用家的應用程式。對做 AI 研究、影音理解評測,或者想分析模型有沒有偷懶靠畫面猜答案的人,會特別有參考價值。