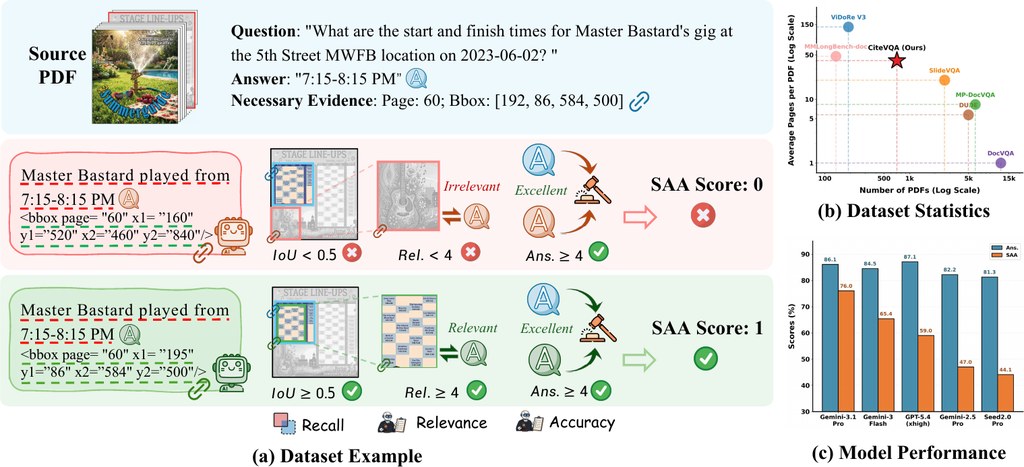
做文件問答評測時,很多工具只睇最後答案啱唔啱,但現實上,尤其是合約、財務報告、醫療文件呢類長篇 PDF,真正重要的是「答案來自邊一頁、邊一段、邊個區塊」。CiteVQA 針對的正正是這個缺口:它不只要求系統回答問題,仲要指出支撐答案的文件位置,而且細到元素層級,例如頁碼同區域框選。對想評估文件 AI 是否可靠的人來講,這比單純比拼答題分數實用得多。
實際使用上,這個專案較適合作為評測基準,而唔係一般用家即開即用的聊天工具。研究團隊、產品開發者或企業內部做文件自動化測試時,可以先取得資料集,再用自己的多模態模型跑推論,之後交畀評估程式比對答案與引用位置是否同樣正確。資料涵蓋英文與中文文件,來自 711 份 PDF、共 1,897 條問題,平均每份文件超過 40 頁,亦分成單一文件問答,以及要在多份文件中找答案的情境,難度相當貼近真實工作流程。
這個專案最值得留意的地方,是它把「答對」與「引對證據」綁埋一齊計分。核心指標 SAA 只有在答案正確,而且引用區域同標準證據對得上時先會得分,能更直接揭示模型有冇出現「講得似乎合理,但引用錯地方」的情況。根據公開結果,即使是表現較強的模型,答案分數與這種嚴格分數之間仍有明顯差距,反映現時不少系統其實未真正做到可追溯。這一點對高風險場景尤其重要,因為用戶要的不只是結論,仲要查得到根據。
重點可簡單整理成以下幾點:
– 不只評分答案,亦檢查引用證據是否真係來自正確頁面與區域
– 文件夠長亦夠真實,涵蓋 7 個大類領域、30 個細分類,並支援中英文
– 場景設計多樣,包括單文件、多文件但只有一份正確來源,以及多份來源都可能成立
– 適合測試文件型多模態模型,特別係要處理 PDF 版面、圖文混合與跨頁搜尋的系統
– 可用來比較模型可靠度,而唔係只比較誰的答案最似正解
從模型觀察角度看,這個基準亦提供了不錯的參考名單。公開結果提到的相關模型包括 Gemini-3.1-Pro-Preview、Gemini-3-Flash-Preview、GPT-5.4、Gemini-2.5-Pro、Seed2.0-Pro、GPT-5.2、Qwen3.6-Plus、GLM-5V-Turbo、Qwen3-VL-235B-A22B、Gemma-4-31B、Kimi-K2.5、Qwen3.5-397B-A17B 等。由這些結果可見,封閉模型在整體表現上暫時較領先,但開源模型同樣能作為對照組,方便團隊用統一方式測試自家方案。對要建立文件審核、知識搜尋、報告核對、法規查證流程的人來說,CiteVQA 的價值不在於幫你直接產生答案,而在於幫你分辨:哪個模型,才真係值得信。