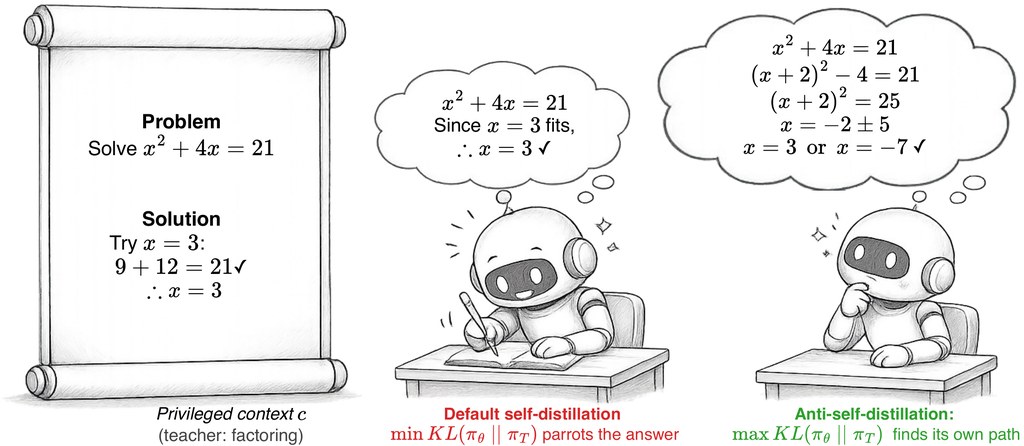
AntiSD 係一個研究型專案,主力處理語言模型做數學推理時嘅訓練偏差。一般做法會叫模型向一個「已知答案、更有提示」嘅自己學習,但作者指出,呢種安排往往會令模型更著重格式化、收尾式嘅字詞,反而削弱真正幫到逐步思考嘅中間推理線索。
呢個專案最特別嘅地方,係將常見嘅自我蒸餾方向反轉。簡單講,唔再一味逼學生版本貼近「已經知道答案」嘅老師版本,而係用一種受控制嘅方式保留兩者差異,等模型唔會過早放棄探索思路;同時再加上一個基於不確定度嘅開關,避免訊號去到後期失控。
實際睇法上,呢個方法唔係畀一般用家即裝即玩,而係較適合已經做緊推理模型訓練、想比較不同強化學習策略嘅人。閱讀論文、配合 GitHub 內嘅實驗設定同 W&B 結果去重現,會係較合理嘅使用方式;重點係觀察訓練步數、最終準確率,同埋模型喺中間推理字詞上有冇被過度壓縮。
- 針對數學推理訓練中「答案啱,但思路變薄」嘅問題
- 核心做法係反轉自我蒸餾訊號,而唔係沿用標準貼近策略
- 論文提到以 pointwise mutual information 解釋點解方法有效
- 在多個 4B 至 30B 模型上,據報可用更少訓練步數追平或超過基線
- 相關模型包括 Qwen3-4B、Qwen3-8B,以及其他同級 4B 至 30B 語言模型
以定位來講,AntiSD 比較似一個畀研究員同模型工程團隊參考嘅訓練配方,而唔係面向終端用戶嘅應用程式。對於關注 AIME、HMMT、BeyondAIME 呢類數學推理基準,或者正用 GRPO 一類方法微調模型嘅團隊,呢個專案提供咗一個值得認真比較嘅替代方向。