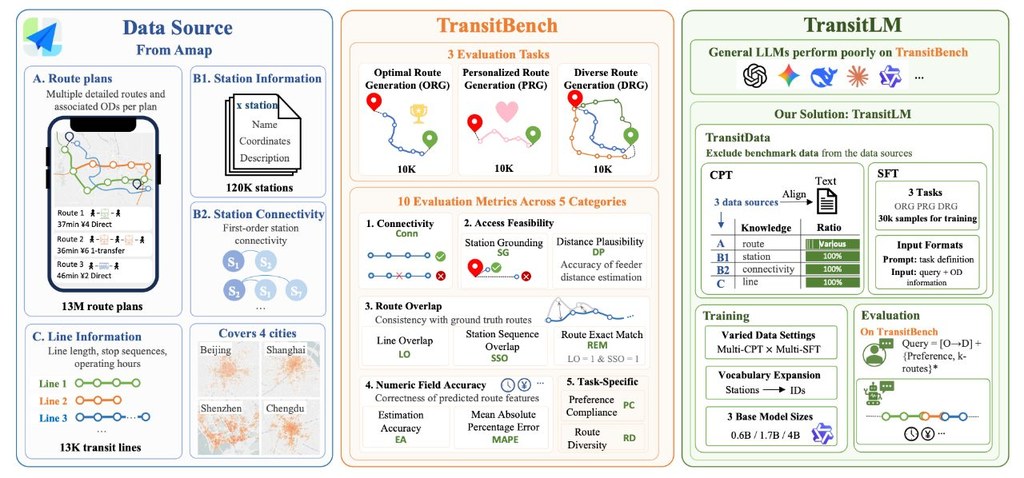
TransitLM 重點不是直接幫你找車程,而是提供一套評估流程,專門量度模型生成公共交通路線的表現。它配合同名論文與資料集使用,主要服務「不靠地圖引擎、直接由資料學出路線」這類研究方向。
項目已經附上示例 CSV,並按不同情境分成幾個評估腳本,包括單一路線、偏好路線、多路線多樣性,以及透過遠端 API 評估一般大語言模型輸出。因為只依賴 Python 標準函式庫,環境要求相對輕巧,想重現論文評估流程的人會較容易開始。
這個項目最值得留意的地方,是它不只給一個總分,而是把結果拆成多層來看,例如路線是否可達、站點是否對應得上、整體結構是否一致,以及時間、距離、票價估算是否可信。對比只看「答得似唔似」,這種分層做法更容易找出模型到底是認錯站、接錯線,還是只在數值估算上失準。
- 支援四類評估情境,覆蓋論文基準與一般 LLM 輸出
- 評分拆成多個維度,比單一總分更有診斷價值
- 可檢查偏好是否符合,例如少轉車、避開地鐵等
- 多路線模式會額外比較替代路線與多樣性
- 安裝負擔低,適合重現與快速驗證
從論文資訊看,TransitLM 背後資料規模相當大,涵蓋超過 1,300 萬筆公共交通規劃紀錄、四個中國城市、120,845 個站與 13,666 條路線;相關研究亦提到模型可在沒有明確地圖對接下,學到站點對應與路線結構。不過這個儲存庫本身偏重「評估」而非「訓練」,所以較適合研究人員、做交通路線生成的模型開發者,或者想比較 GPT、Qwen 這類一般模型在路線任務上表現的人。
整體來看,TransitLM 的價值在於把一個很易流於主觀的任務,整理成可重現、可分解、可比較的評估項目。對非專業讀者來說,可以把它理解成一把較精細的尺:不是幫你直接畫路線,而是幫你判斷模型畫出來的路線,到底有幾可信。