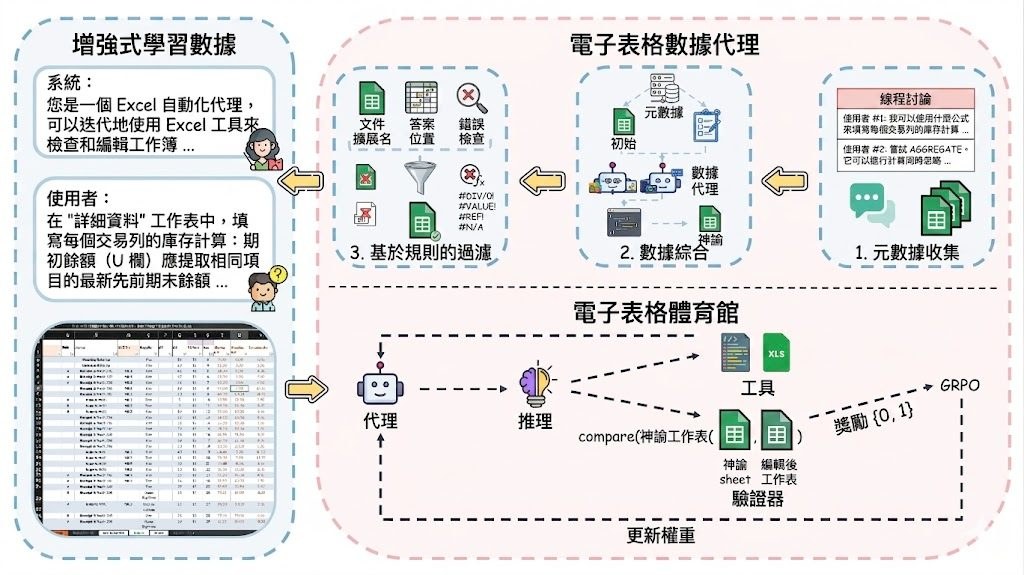
Spreadsheet-RL 是一個針對試算表工作的強化學習項目,重點不是單次輸出答案,而是讓大型語言模型在 Microsoft Excel 環境中分步操作,最後再用整份活頁簿的結果判斷做得對不對。對比一般只靠提示詞的方法,這種設計更貼近日常表格整理、計算和修正流程。
它解決的核心問題,是模型面對多步驟試算表任務時,往往容易中途出錯,或者只懂講做法但未必真的完成。這個項目把資料建立、互動環境、獎勵機制串連起來,令訓練目標不只是「說得像」,而是「做得啱」。當系統會重新計算並比對最終活頁簿,評分方式就比純文字答案更實在。
上手方向也算清楚:研究者可用它提供的訓練與評估堆疊,配合 Excel 獎勵服務、沙盒程式執行,以及多輪互動環境,去訓練或測試自己的試算表代理。內容明顯較適合具備機器學習、叢集運算或代理系統背景的人,普通用家未必會直接部署,但很適合拿來理解「AI 幫你做 Excel」背後需要哪些能力。
幾個值得留意的位包括:
– 以公開試算表論壇題目自動整理訓練資料,論文提到有 5,928 個經篩選任務
– 支援多輪 Excel 互動,而不只是一次生成答案
– 內建試算表原生工具、沙盒執行程式碼,以及獨立工作空間
– 以最終活頁簿正確性作為獎勵,較貼近真實工作成果
– 已公開 Spreadsheet-RL-4B,基於 Qwen/Qwen3-4B-Thinking-2507 訓練
表現方面,論文提到 Qwen/Qwen3-4B-Thinking-2507 經完整流程後,SpreadsheetBench 的 Pass@1 由 12.0% 提升到 23.4%,另一個 Domain-Spreadsheet 評估則由 8.4% 升至 17.2%。幅度相當明顯,但仍屬研究型結果,使用時也要留意其環境依賴較重,包括 Excel 服務、沙盒與訓練基建。
整體來看,Spreadsheet-RL 最有價值的地方,是它把「試算表代理」由提示工程推前一步,變成可訓練、可評估、可重現的完整項目。相關模型方面,文中可見 Qwen3-4B-Thinking-2507、Qwen3-4B Instruct、Qwen3-8B、Qwen3-14B、Qwen3-32B,以及 GPT-4o、OpenAI o3 等比較基線;對想研究 AI 自動處理表格工作的人,這是一個很值得留意的參考。