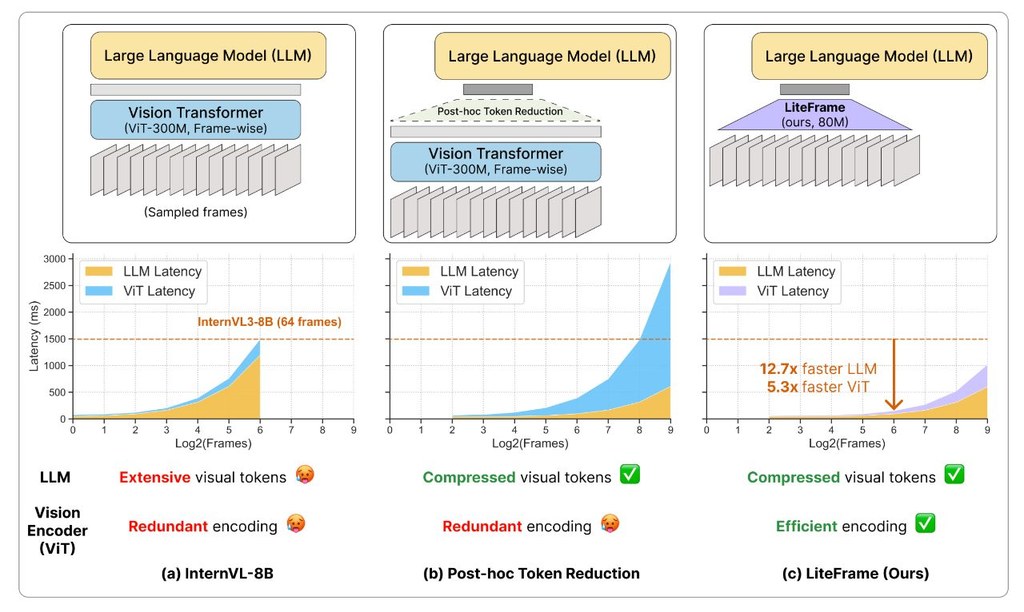
而家不少影片大模型都可以答片段問題、做內容理解,但片一長,速度同成本就會急升。LiteFrame針對的正正唔係表面上的「睇少啲格」,而係指出每一格都交俾大型視覺編碼器處理,本身先係真正慢位。
這個專案提出一個較輕量的影片編碼骨幹,核心做法是用較大的教師模型,教一個更精簡的學生模型直接產生已壓縮、但仍保留時空資訊的表示。論文將這套訓練方式稱為 Compressed Token Distillation,另外亦配合 Language Model Adaptation,令後續語言模型更易接住使用這些視覺資訊。
對使用者而言,現階段較適合作為研究參考而非即裝即用工具,因為 README 已說明程式碼和權重尚未釋出。實際閱讀可以先由論文和項目頁入手,集中看它如何比較端到端延遲、可處理影格數,以及在多個影片理解基準上的準確度變化。
- 重點不只是減少語言模型負擔,亦直接降低逐格視覺編碼成本
- 主打長影片理解,在固定運算預算下處理更多 frames
- 論文提到相對 InternVL3-8B,可降低端到端延遲並處理更多影格
- 適合做影片問答、影片描述、時序推理相關研究參考
- 文中脈絡亦關連到 Video LLM、MLLM、ViT、InternVL3-8B 等模型路線
整體來看,LiteFrame的價值在於把焦點由「事後刪 token」移前到「一開始就更有效率地抽特徵」。對關注長片分析、影片助手或多模態系統的人來說,這是一條幾實際的新方向,不過最終落地效果仍要等官方釋出程式碼與模型後,先可以更完整驗證。