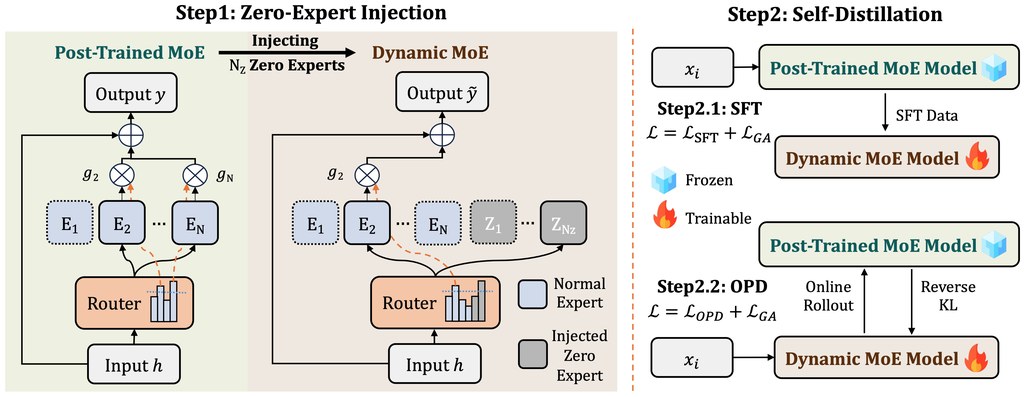
ZEDA 針對的是一個很實際的痛點:大型 MoE 模型雖然強,但部署時每次回應都要動用唔少計算資源,成本高、速度亦受影響。呢個專案的目標,係唔使由頭再訓練模型,而係在現有、已做完後訓練的 MoE 之上,再改造成更靈活的動態版本。
它的做法有點似「老師帶學生」:先用原本的 MoE 當固定老師,再訓練新的學生模型去學習輸出,同時加入一種零輸出的專家,讓部分較簡單的 token 可以略過不必要計算。根據論文與倉庫資訊,這種方法可減少超過一半 expert FLOPs,整體表現只屬輕微下跌,並帶來約 1.20 倍端到端推理加速。
ZEDA 不是通用開發框架;它是清華 C3I 團隊的一個研究專案,從公開論文摘要看,全名是 Zero-Expert Self-Distillation Adaptation,目標是把靜態 MoE 模型轉成更高效的動態 MoE 模型,以降低推理成本並提升速度。這個專案對應的 GitHub 倉庫就是 TsinghuaC3I/ZEDA,而論文頁面也明確指向該 repo。
實際動手時,流程大致分兩步:先做 SFT,利用老師模型產生的回應或已釋出的 rollout 結果訓練學生;之後再做 OPD,改為由學生自己生成,再由老師提供 token 級別目標去微調。倉庫亦提到可配合已公開的 prompts 與 rollout 資料使用,對想重現結果或套用到指定 MoE 的人會方便不少。
- 核心價值:把已完成訓練的靜態 MoE,改成推理時更慳算力的動態 MoE
- 方法亮點:加入零輸出專家,再用兩階段自蒸餾穩定轉換過程
- 可選模型:Qwen3-30B-A3B、GLM-4.7-Flash
- 適合場景:模型已定版,但上線後仍想再壓低推理成本
- 資料配套:提供 prompts 集合,亦釋出部分 rollout 結果可直接利用
整體來看,ZEDA 最值得留意的地方,不是單純追求更高分,而是補上「模型已經訓練完,之後仲可以點樣再慳資源」這一步。對研究 MoE 部署、推理優化,或者手上已有大型後訓練模型的團隊,這個方向相當有參考價值;至於一般讀者,可以把它理解成一種用較少電腦功夫,換來差不多效果的改裝方案。