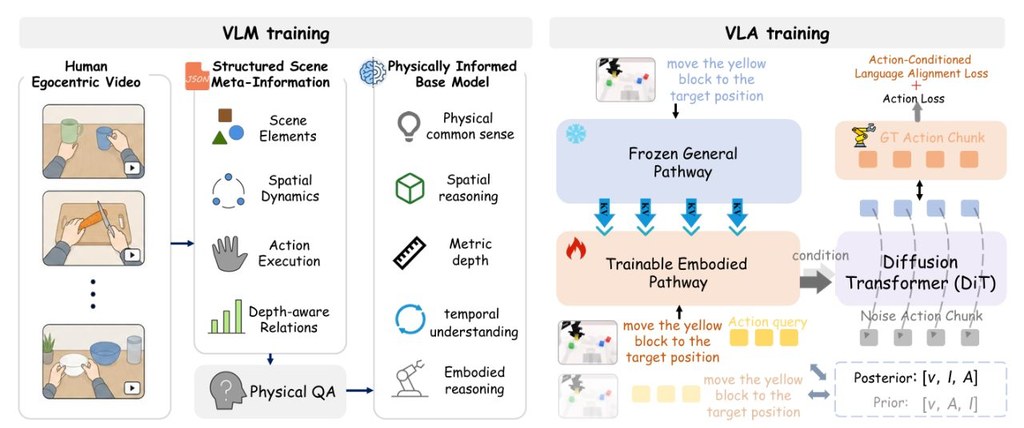
PhysBrain-VLA 係一個面向機械人控制的研究專案,但它最值得留意的地方,其實係訓練思路改變咗。以往不少系統主要靠機械人示範資料學動作,成本高之餘,遇到新場景亦未必識變通;而呢個專案就主張先由大量人類第一身影片抽取「物理常識」,再轉化畀模型學習。
對一般讀者嚟講,可以將它理解為:與其死記「點樣拎起杯」,不如先明白杯喺枱上、手要接近、物件有前後高低關係,甚至某些動作做唔做到。根據公開資料,團隊處理咗超過 3,000 小時人類影片,並整理成包含空間關係、動作可行性同推理線索的多模態訓練資料。
如果你想上手理解這個專案,較實際的方法唔係直接當成即裝即用工具,而係先由它的整體架構入手:先看資料引擎點樣把影片轉成結構化訊息,再看基礎模型如何吸收這些知識,最後理解 VLA 部分點樣把理解能力轉成機械人動作。對研究員、機械人開發者,或者關心 embodied AI 發展方向的人,呢個閱讀路線會比較清晰。
- 核心價值係減少對昂貴機械人示範數據的依賴
- 主要做法係由人類第一身影片提煉物理與空間常識
- 架構包含 PhysBrain、TwinBrainVLA、LangForce
- 提到的評測包括 ERQA、PhysBench、SimplerEnv-WidowX、LIBERO、RoboCasa
其中較有新意的是 TwinBrainVLA 的雙腦式設計,目標是減輕微調後「學咗新嘢就忘記舊嘢」的問題;LangForce 則把訓練重心由單純模仿行為,轉向較貼近物理推理的學習方式。從論文摘要來看,它在多個理解與控制評測都有強表現,尤其在陌生環境的泛化能力方面值得關注。
整體而言,PhysBrain-VLA 未必係面向普通用家的產品型專案,但作為技術方向,它展示咗一條幾實際的路:先讓模型理解世界,再叫它出手做事。若你想追蹤未來機械人如何由「照做」走向「識判斷」,這個專案相當有參考價值。
Project Page: https://phys-brain.github.io