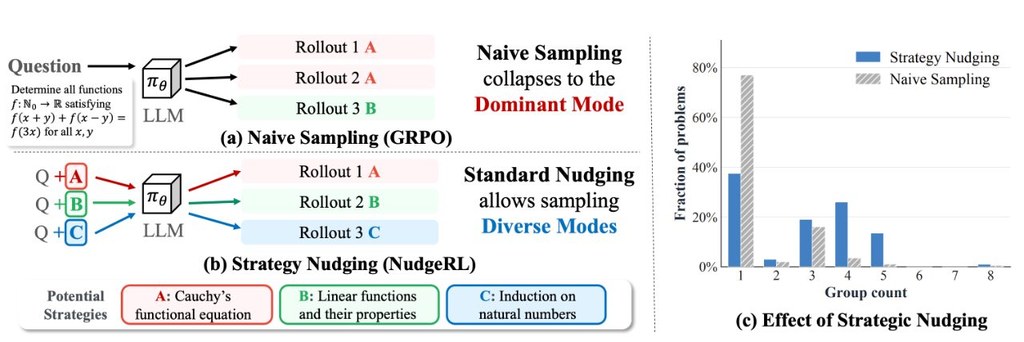
如果你有留意近年大語言模型點樣練習數學題,NudgeRL算係一個幾有方向感的研究型專案。佢主要針對一個常見問題:模型唔係唔努力,而係好多時只會喺自己熟悉的解題路線入面打轉,結果要靠大量重複抽樣先撞到更好答案。
NudgeRL的做法唔係一味加大運算量,而係先提供較輕量的「策略層面背景」,引導模型用唔同思路展開推理,再將當中有效的行為學返去原本模型。簡單講,即係先畀方向去探索,再將成功經驗整理吸收,呢點比純粹盲試更有系統。
實際上手方面,呢個儲存庫已經分好幾部分:資料建立、訓練基線、NudgeRL訓練,同埋評估流程。較適合本身已經會用 Python、PyTorch、CUDA 同 vLLM 的研究者;如果你係一般開發者,都可以先由評估腳本、資料格式同設定檔入手,理解整體流程先。
- 針對數學推理中的探索不足,而唔係只求更大抽樣數量
- 內置 GRPO 同 POPE 風格基線,方便比較方法差異
- 提供 DAPO-Math-17k 相關資料建構工具,唔使由零砌流程
- 評估涵蓋 AIME、AMC23、MATH500、Apex Shortlist 等數學基準
- 核心特色係將多樣化策略探索同後續行為蒸餾結合
如果你想比較相關模型或訓練路線,呢個專案最直接涉及的包括以 GRPO 為代表的 RLVR 方法、POPE 風格 oracle-prefix 基線,以及可配合 Hugging Face 模型與 LoRA adapter 的訓練評估流程。整體而言,NudgeRL較適合做推理增強、數學能力研究、後訓練方法比較的人;對想了解「如何更有效探索」而唔係「如何堆更多算力」的讀者,尤其有參考價值。