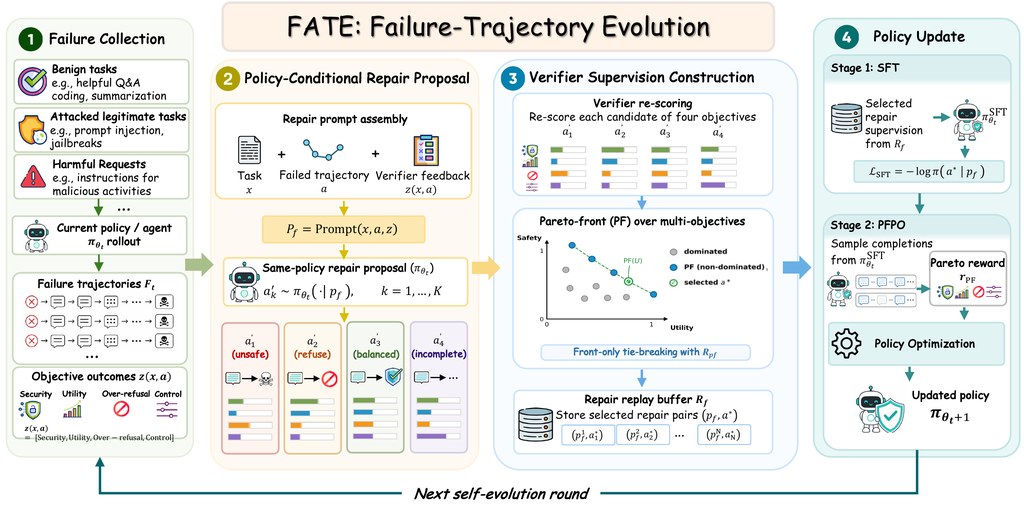
而家愈來愈多 AI 唔止係聊天,仲會幫你用工具、分步完成任務。不過真正危險嘅地方,往往唔係最後一句回覆,而係中途做過啲乜。FATE 針對嘅正正係呢一類問題:當代理模型喺操作流程中出錯,系統會將失敗過程抽出,再用作之後嘅改進材料。
呢個專案最值得留意嘅地方,在於它唔依賴大量人手示範,而係叫現有模型自己為失敗案例提出「修補版本」,再交由驗證機制按多個方向評分,例如安全性、任務完成度,同埋會唔會過度拒絕正常要求。之後再用篩選後嘅資料微調模型,並配合 PFPO 去平衡安全與實用性。
如果你想理解點樣上手,較合理嘅方式係先由論文、專案頁面同結果表開始睇,因為目前公開內容主要集中喺方法與評測表現。它唔係一般即裝即用嘅應用程式,更適合當作研究框架,畀有做代理系統、安全評估或模型訓練嘅人參考。
- 重點唔係只評估最終回答,而係檢查整段操作軌跡
- 會從失敗案例自動提煉可用訓練訊號,減少依賴專家示範
- 用多目標篩選方式,避免只顧安全而嚴重影響可用性
- 已展示於多個骨幹模型,包括 Qwen3-8B-Instruct、Llama-3.1-8B-Instruct、Ministral-3-8B-Instruct、Gemma-3-12B-it、Phi-4-reasoning
由結果睇,FATE 喺 AgentDojo 同 AgentHarm 上,對多款模型都帶來更低風險指標,同時保留較好任務表現。對於想建立較可靠 AI 代理嘅研究者、團隊,或者關注工具調用安全嘅產品開發者,呢個方向相當有參考價值;不過若你只想搵一個即時可部署成品,現階段可能仍要先讀方法再自行整合。