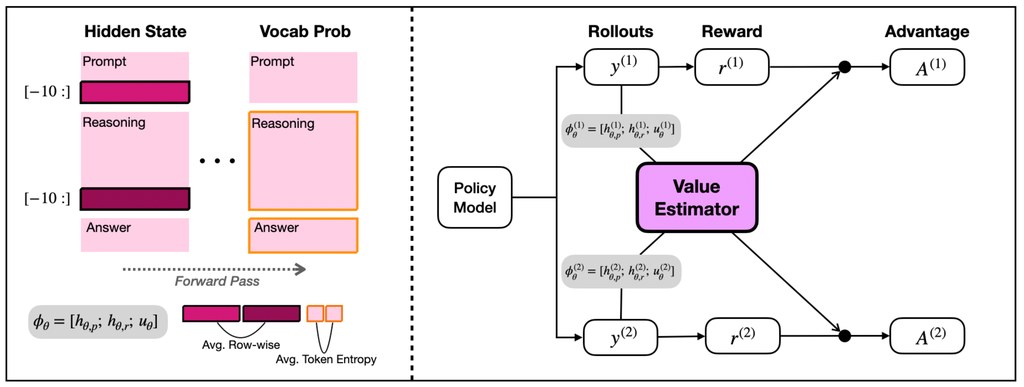
POISE 是一個用於語言模型強化學習的方法,重點是讓模型在生成答案時,直接利用自己已有的隱藏狀態與熵等訊號,估計回報基線。簡單來說,它希望模型「一邊作答,一邊判斷自己表現大概應該有幾好」,從而更有效更新訓練方向。
實際使用上,這類方法特別適合有可驗證結果的任務,例如數學題最終答案是否正確。傳統做法通常要額外訓練一個 critic 模型,或者對同一提示做多次 rollout 來估基線;POISE 則改為重用 actor 本身生成時已計算出的資訊,理論上可減少訓練成本。
它的主要創新,在於把模型內部表徵重新納入 RL 更新流程,而不是依賴獨立的大型評分器。網站內容指出,這個估值器會隨政策變化持續更新,配合當前及近期 rollout,目標是令線上學習更穩定。
- 以 actor 自身隱藏狀態做 value estimation
- 不需要獨立 critic 模型
- 減少同一 prompt 的額外取樣開銷
- 適合有明確對錯驗證的任務
- 著重更輕量與穩定的 RL 訓練流程
在初步評估方面,POISE 在 held-out 的 DAPO-Math rollouts 上,內部狀態探針的 Pearson r 為 0.870、MAE 為 0.141。對比一個由 Qwen3-4B 微調而成的 critic,其 r 為 0.676、MAE 為 0.262,顯示 actor 內部訊號至少在這項基準中具有不錯的預測能力。
受惠工作包括數學解題、可程式驗證推理,以及其他能以結果回饋作訓練的語言模型流程。不過目前頁面展示內容以方法概念與初步結果為主,較完整的泛化表現與不同任務上的最終效益,仍要留意論文後續公開分析。
實驗結果
| 模型 | 方法 | Avg@32 (數學推理) | 訓練時間 (B200 GPU) |
|---|---|---|---|
| Qwen3-4B | DAPO | 0.508 | 49 小時 |
| Qwen3-4B | POISE | 0.500 | 36 小時 |
| DeepSeek-R1-Distill-Qwen-1.5B | DAPO | 0.296 | 24 小時 |
| DeepSeek-R1-Distill-Qwen-1.5B | POISE | 0.303 | 18 小時 |
POISE 在數學推理基準 (AMC23/24, AIME24/25/26, HMMT25, BRUMO25) 上達到與 DAPO 相當的性能,但計算成本更低 。